
Denotation doesn’t cut it, baby!
Hanna Reininger nutzt das DeepL-Plug-in im CAT-Tool Wordfast und dabei bleibt kein Stein auf dem anderen.
Im Rahmen von Workflow 6 sollte ein Auszug aus dem Liebesroman Meet Me in the Margins von Melissa Ferguson mit Hilfe eines CAT-Tools übersetzt werden, in das neben DeepL auch ein Glossar eingebunden wurde. Der Ausgangstext (AT) schien grundsätzlich für eine maschinelle Übersetzung (MÜ) geeignet. Er wies nur kleinere Fehler bzw. Inkongruenzen auf:
– S. 1, Zeile 04: outstanding[ly] uncomfortable
– S. 1, Zeile 13: … thin heel at [and] take a …
– S. 2, Zeile 14 bzw. S. 3, Zeile 11: Ms. Pennington
– S. 3, Zeile 21: Mrs. Pennington
Der AT enthielt Merkmale literarischer Texte, beispielsweise:
– Gegensätze, Ironie: begrudgingly accommodating; rare bursts of genuine motivation — or … prods me until I give in; …
– intratextuelle Bezüge: outstanding[ly] high heels; red carpet … slashing three words; …
– Wiederholungen, Rhythmus: not an inch over five feet tall; I am a Cade. Specifically, Savannah Cade.; …
– Alliteration: benefits of being an assistant acquisitions editor; flicker as I flip from one page; exceeding expectations; …
– Metapher: solid chugging of the bigger … machines; Pennington is a sailboat; …
Der holprige Weg zum Glossar
Als ersten Schritt erstellte ich mit D-Terminer, einer internet-basierten Software, die aus einem Text relevant erscheinende Termini herausfiltert, ein Glossar.
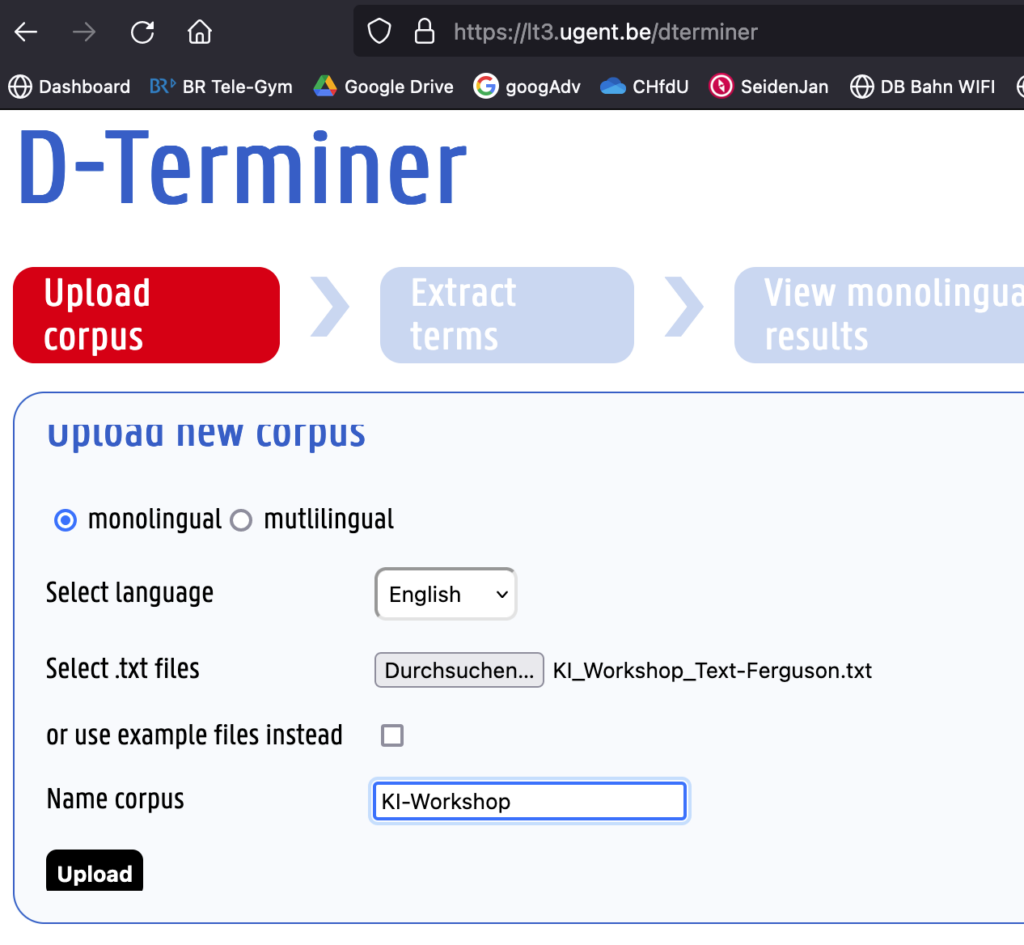
D-Terminer schlug 47 Termini vor, die ich auf 10 konsolidierte, indem ich nur die mehr als einmal im Text vorkommenden Begriffe beibehielt. Einige Satzzeichen (halbe bzw. ganze Anführungszeichen) wandelte D-Terminer in Ō bzw. Ṇ, daher bedurfte es etwas zusätzlicher Nacharbeit.
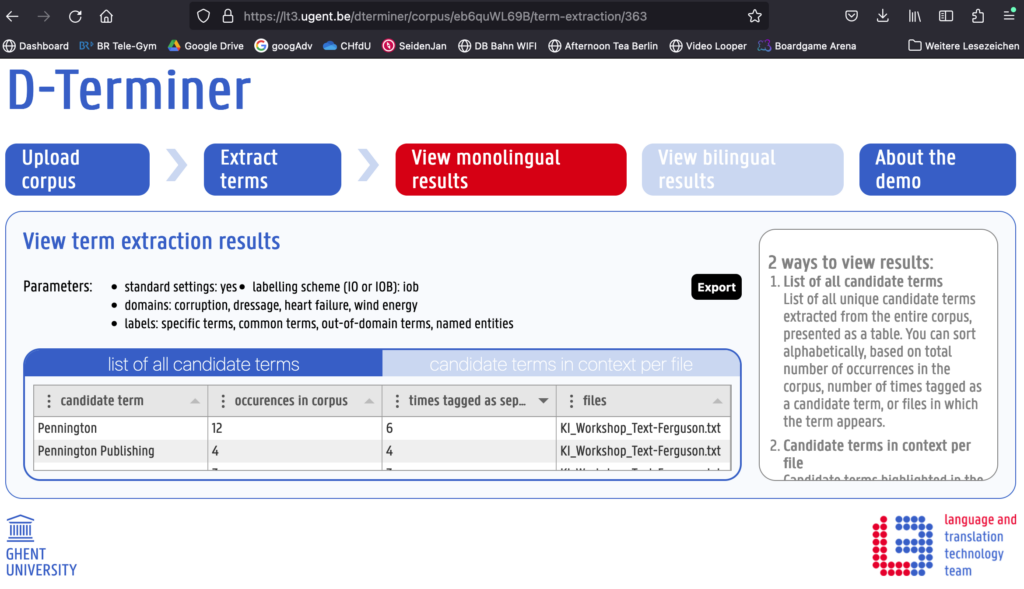
Dann importierte ich das Glossar mit den AT-Termini Pennington, Pennington Publishing, eyes, words, multitask, Cade, word, pen, Ms. Pennington, podium und ihren von mir vorgegebenen Zielsprachen-Entsprechungen in das CAT-Tool Wordfast.
Automatische Übersetzung mit Wordfast
Das Tool zerlegt den AT in Segmente, meist ganze Sätze. Anhand eines online gefundenen Tutorials verlief dies – wie auch die Einbindung von DeepL – problemlos. Nachdem die Hinterlegung des Glossars zunächst in den Standardformaten .tsv/.csv scheiterte, klappte es mit einer .xls-Datei.
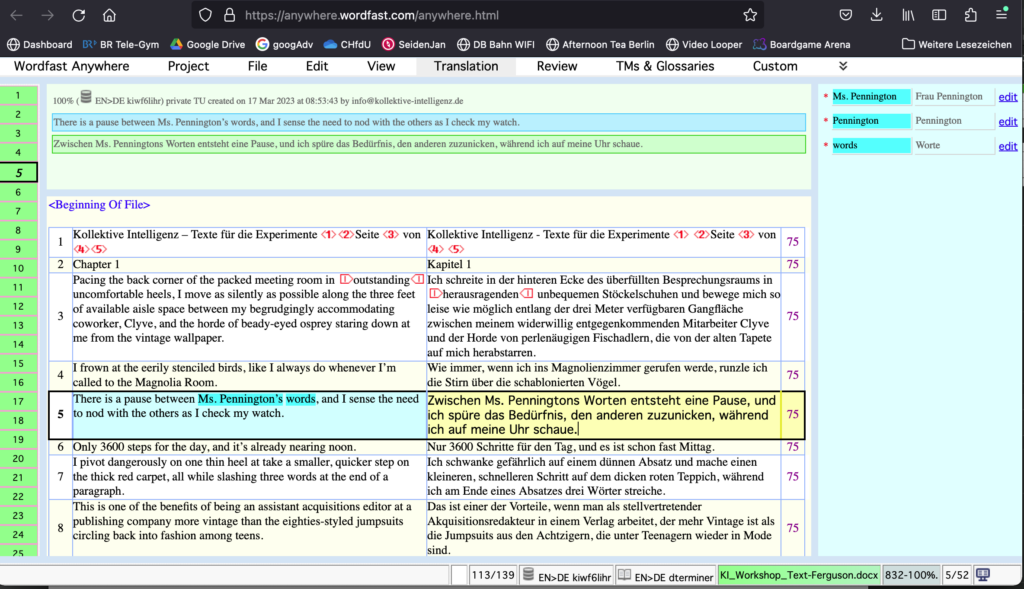
Die MÜ (durch Einbindung von DeepL) erfolgte dann in weniger als einer Sekunde pro Segment, so dass schon nach sehr kurzer Zeit ein Zieltext (ZT) zur Verfügung stand. Nach erster Sichtung stellte sich heraus, dass die Vorgaben des Glossars darin nicht übernommen worden waren (z. B. Findling für Cade, Pult für podium). Das DeepL-Plug-in scheint eine Art Override-Funktion zu haben, die sich nicht deaktivieren lässt. Lediglich einem Translation Memory kann man in Wordfast Vorrang gegenüber dem DeepL-Plug-in einräumen.
Der Export des ZT in Word verlief problemlos. Grundsätzlich lag also bereits nach wenigen Handgriffen eine MÜ vor. Der zeitliche Aufwand von insgesamt ca. 20–30 Minuten lässt sich mit steigender Routine gewiss noch senken.
Das meiste geschieht in Word
Anschließend prüfte ich den ZT auf Stimmigkeit und Literarizität und überarbeitete ihn im Word-Änderungsmodus. Wie am Dokument ersichtlich ist, blieb dabei »kein Stein auf dem anderen«. Die MÜ blieb sehr nah am Wortlaut des AT. Der entstehende ZT wies somit in Satzbau und Idiomatik eine hohe Anzahl Interferenzen (im Deutschen untypische, englische Formulierungen) auf – der Text war klar als Übersetzung zu erkennen. Bezüge zwischen den Sätzen wurden nicht beachtet, beispielsweise das Geschlecht einer handelnden Figur. Viele der gewählten Entsprechungen erschienen nicht optimal. Vor allem die inhaltliche Korrektheit, Wortwahl, intertextuellen Bezüge und der Stil des ZT ließen zu wünschen übrig. Die Ironie der Erzählstimme, ihre unterhaltsamen Erläuterungen zu sich selbst und ihrer Umgebung übertrug sich nicht im erforderlichen Maße. Eine Auswertung in Anlehnung an die TAUS-Fehlertypologie stellt sich wie folgt dar:
Inhaltliche Korrektheit: eher viele Fehler
– Auslassungen: sehr wenige
(S. 1, Zeile 8 eerily nicht übersetzt)
– Fehler, interne Bezüge nicht korrekt: viele
(keiner der Augen in den Reihen vor mir; weil ich ein[e] Cade bin; Pennington ist ein Segelboot … dessen Besitzer[in] … während er [sie]; Die letzten Jahre waren nicht einfach … Nicht nur wir [für uns]; …)
– Fehler, mangelhafte Wortwahl: viele
(Mitarbeiter – coworker; perlenäugig – beady eyed; spüre das Bedürfnis – sense the need; kein Auge flackert – none of the eyes flicker; ergreift das Podium – gripping the podium [lectern]; dümpelnder Fleck – bobbing speck; …)
– Fehler, mangelnde Stringenz: einige
(feet sowohl mit Meter als auch m übersetzt; Pennington Publishing sowohl belassen als auch mit Pennington-Verlag übersetzt; Ms. P… mit Frau P…n übersetzt, aber Mrs. P… belassen)
Sprachliche Korrektheit: eher wenige Fehler
– Grammatik: wenige Fehler
(… von denen wir glauben, dass die Welt lesen muss; … ob die ganze Welt von und meine letzte Bearbeitung haben muss)
– Rechtschreibung: keine
– Register: keine
– Widersprüchlichkeit: wenige Fehler
(Geschlechtszuordnung teils falsch)
– Zeichensetzung: wenige Fehler
(engl. “ “ anstelle deutscher » «; content mit -Inhalte übersetzt)
Stil: eher viele Fehler
– Unidiomatische Ausdrücke / Wortwörtlichkeit: viele
(… entlang der … verfügbaren Gangfläche; perlenäugige Fischadler; 3600 Schritte für den Tag; Zwischen … Worten entsteht eine Pause; dicke Papierstapel mit Stiften hinter den Ohren; …)
– Stilbrüche: keine
– Unangemessenheit: wenige
(reine Rasse – für Personen im Deutschen nicht politically correct)
Terminologie, Begriffe: eher viele Fehler
(wegen mangelnder Möglichkeit der Voreinstellung)
Form, Locale, Faktizität: eher viele Fehler
– Textlänge: + 15 % (AT: 4.797 Z; ZT: 5.568 Z)
– Formatierung: i. O.
– Format: Maße umgerechnet, aber jeweils falsch
(3 feet mit 3 Meter übersetzt, 5 feet mit 1,80 m)
– Kulturspezifische bzw. außertextliche Bezüge: einige
(Kapitel 1 anstelle 1. Kapitel; Kursivsetzungen übernommen, obwohl im Deutschen eher unüblich)
Auf die Überarbeitung des Textes folgte noch ein Kontrolldurchlauf, in dem ich einige letzte Präzisierungen und Korrekturen vornahm. Der Zeitaufwand für die Übersetzung samt nachlaufender Überarbeitung betrug insgesamt ca. 2,25 Stunden. Damit war der zeitliche Aufwand der MÜ mit nachgelagerter Überarbeitung nicht geringer als die Erstellung einer Übersetzung durch ein Human-Übersetzy.
Fazit: Hoher Aufwand
Die hohe Fehlerrate zog einen erheblichen Überarbeitungsaufwand nach sich. Dabei mussten auch die zu Beginn genannten Merkmale literarischer Texte »händisch nachjustiert« werden. Hinsichtlich der sprachlichen Korrektheit war die MÜ nur wenig fehlerhaft. Dies ist meines Erachtens ein Indiz dafür, dass die MÜ brauchbare Ergebnisse liefert, solange der AT hauptsächlich informativ ist, also die rein denotative Ebene der Wörter relevant ist. Die falsche Umrechnung der im Text angegebenen Maße hat mich allerdings überrascht. Doch bei literarischen Texten kommt – im Gegensatz zu Sachtexten – auch die konnotative Ebene der Wörter zum Tragen. Textform und -inhalt sind untrennbar miteinander verbunden. Hier lieferte die MÜ kein zufriedenstellendes Ergebnis.
Human-Übersetzys analysieren die literarischen Merkmale des AT im Vorfeld ihrer Arbeit, um diesen in ihrem ZT Rechnung tragen zu können. Bei der MÜ erfolgt eine solche Analyse nicht. Würde der AT beispielsweise vorab zusätzlich auf ästhetische Form-Merkmale wie Alliteration, Wiederholungen, Rhythmus, Ironie etc. analysiert (zumindest die ersten drei Punkte sollten sich maschinell »erkennen« lassen) und bei der Übersetzung entsprechend imitiert oder – wo nicht möglich – durch adäquate, ähnlich wirkende Merkmale ersetzt, ließe sich eventuell ein besseres Ergebnis erzielen.
Die MÜ lieferte sehr schnell ein dem grundsätzlichen Handlungsstrang folgendes Text-Grundgerüst, das in Satzbau bzw. Satzlänge ungefähr dem AT entsprach – in allen anderen Aspekten tat es dies jedoch nicht. Mangels vorgeschalteter Form-Analyse war das Gerüst nicht adäquat »ausgekleidet«. Der Arbeitsaufwand des »Post-Editing«, sprich der umfassenden Überarbeitung mit dem Ziel, einen der Humanübersetzung gleichwertigen ZT zu erhalten, war beträchtlich. Das Text-Gerüst musste komplett freigelegt und neu ausgekleidet werden.
Insbesondere bei humorvollen Texten scheint die MÜ derzeit noch nicht in der Lage, einen ZT zu produzieren, der die literarische Wirkung des AT erzielt. Die kombinierte Einbindung eines Glossars und DeepL-Plug-ins in ein CAT-Tool entpuppte sich als nur wenig zielführend. Die Einbindung eines mit vielen literarischen Texten hinterlegten Translation Memory würde wahrscheinlich bessere Dienste leisten. Nicht zuletzt, weil man diesem den Vorrang vor der MÜ einräumen kann.
Review
von Imke Brodersen
Von einem Unterhaltungsroman erhoffe ich mir eine spritzige Erzählung, in der Protagonistin, Setting und Konflikte mich spontan fesseln. Mit dieser Erwartungshaltung nahm ich in einer Lesedatei alle Änderungen aus der bereitgestellten Schlussversion an und begann mit der Lektüre, ohne zuvor den Ausgangstext zu lesen.
In einem Verlag setzen an dieser Stelle Lektorat und Endkorrektur an. Nach den ersten Abschnitten wechselte ich die Rolle und lektorierte das Manuskript rigoros, weil einzelne Stellen mir inhaltlich unklar waren: Die Tapetenbeschreibung erschloss sich mir erst nach einer Bildersuche anhand der englischen Originalformulierung; bei den »Overalls« als Beispiel für angesagte Retro-Mode aus den 1980ern stutzte ich, prüfte Originaltext und Modetrends und identifizierte sie als »Latzhosen«. Die bereitgestellten Zwischenversionen belegen, wie leicht Schwächen der maschinellen Vorübersetzung aufs Glatteis führen und zusätzlichen Abstimmungsbedarf zwischen Übersetzerin und Lektorat erzeugen.
Eigennamen hatte die maschinelle Übersetzung beibehalten, obwohl die Übersetzerin sich entschieden hatte, diese zu verändern, und dafür ein Glossar angelegt hatte. Diese Vorgabe wurde von der Maschine ignoriert. Bei einem langen Manuskript mit einem großen Glossar wäre die Korrektur derartiger Fehler sehr aufwändig.
Vereinzelte Zeichensetzungs- und Grammatikfehler als Überreste der umfassenden Überarbeitungen der maschinellen Übersetzung zeigen, dass ein externes Schlusskorrektorat unabhängig von den übersetzerischen Entscheidungen nicht entfallen kann.
Der Ausgangstext nutzt bestimmte, im Reflexionstext benannte Stilelemente, um die Einstiegsszene stimmig zu gestalten. Diese rhetorischen Stilmittel wollte die Übersetzerin möglichst erhalten. Damit sie bei einem Unterhaltungsroman das Lesevergnügen erhöhen, ohne den Zugang zu erschweren, muss man sie bei einem KI-generierten Text bewusst nachträglich einflechten und passende Stellen dafür finden.
Warum ich so gern für einen besseren Textfluss straffen wollte, verstand ich erst beim Blick in die Reflexion der Übersetzerin zum Arbeitsprozess, das Original und die Zwischenversionen.
Laut Reflexionstext waren Fehlerbehebung und Überarbeitung der Vorübersetzung mindestens so zeitaufwändig wie eine eigenständig angefertigte Übersetzung. Die neuronale maschinelle Unterstützung spart demnach am Ende weder Zeit noch Geld, zumal trotz nachweislich gründlicher Arbeit (Glossarerstellung, maschinelle Vorübersetzung, erste und zweite Überarbeitung) immer noch ein kritisches Lektorat und eine Schlusskorrektur nach dem Vier-Augen-Prinzip erforderlich sind.
Insgesamt scheint die maschinelle Vorübersetzung das unvoreingenommene Erfassen von Szenen und Personen zu erschweren, das zum Übersetzen von Erzählungen unabdingbar ist. Im Einzelfall wird eine vorgeschlagene Formulierung unzureichend hinterfragt, weil in der Vorübersetzung so vieles schief klingt und das Gehirn keine stimmigen, eigenen Bilder mehr erzeugt. Diese Beobachtung deckt sich mit meinen eigenen Erfahrungen im Rahmen der Studie und anderen Selbstversuchen.
Bild: Виталий Сова