
Die Zukunft liegt in automatisierten Tools
Unsere Teilnehmerin unterzieht die Glossarfunktion von DeepL einem gründlichen Test. Die Maschine kann zwar noch nicht glänzen, doch ihr Output wird als beeindruckend gut beurteilt.
Erstellen eines Glossars
Um die Terminologie des Ausgangstexts (AT) für das zu erstellende Glossar zu ermitteln, wurde der Text auf kritische Begriffe hin untersucht.
Um besser beurteilen zu können, welche Wörter und Ausdrücke für die Übersetzungssoftware problematisch sind, wurde ein Auszug des Ausgangstexts probehalber in DeepL eingegeben.
 Im Anschluss daran wurde die in das Tool eingebettete Glossar-Funktion getestet, was sich aber insgesamt in der Handhabung als eher umständlich erwies. Schließlich wurde das Original der Einfachheit halber ausgedruckt und auf für ein Glossar sinnvoll erscheinende Begriffe abgeklopft. Das ist bei längeren Texten allerdings keine Option.
Im Anschluss daran wurde die in das Tool eingebettete Glossar-Funktion getestet, was sich aber insgesamt in der Handhabung als eher umständlich erwies. Schließlich wurde das Original der Einfachheit halber ausgedruckt und auf für ein Glossar sinnvoll erscheinende Begriffe abgeklopft. Das ist bei längeren Texten allerdings keine Option.
Insgesamt scheint die Nutzung der Glossarfunktion für die spezielle Textsorte »Liebesroman« eine eher untergeordnete Rolle zu spielen, ist höchstens für das in der Unterhaltungsliteratur beliebte Format von Romanreihen sinnvoll.
Import der CSV-Datei
Die ermittelten Begriffe wurden mit der als passend erachteten Bedeutung unter MS Excel in eine Tabelle eingetragen, die im CSV-Format abgespeichert und unter Verwendung der entsprechenden Funktion bei DeepL hochgeladen wurde.
In der Folge wurde der AT eingefügt und von dem Tool automatisiert übersetzt.
Schon nach diesem Schritt stellte sich heraus, dass die per Glossar vorgegebenen Übersetzungen nicht grundsätzlich richtig angewendet beziehungsweise streckenweise sogar ignoriert wurden. Das zeigte sich insbesondere bei Maßeinheiten – hier war für die Angabe »three feet« eigentlich »ein knapper Meter« vorgegeben, im übersetzten Text stand jedoch »drei Meter«.
Auch Kombinationen aus Adverb und Attribut sind fehleranfällig, werden gern als Attributreihe übersetzt (z. B. »outstanding uncomfortable heels« statt »bemerkenswert unbequeme« mit »bemerkenswerte unbequeme Stöckelschuhe«). Der Versuch, hier mit einem Glossareintrag vorzubeugen, scheiterte.
Überarbeitung des Zieltextes in DeepL
Im nächsten Schritt erfolgte die Überarbeitung anhand der automatisierten Vorschläge des Übersetzungstools. Diese sind wirklich vielfältig und decken verschiedenste Aspekte ab, dabei durchaus auch Variationen der Satzgliedstellung. Auch das Genus von Personen, das allein anhand des Namens nicht eindeutig bestimmt ist (im konkreten Fall der Kollege/die Kollegin »Clyve«), ließ sich hier vereinheitlichen.
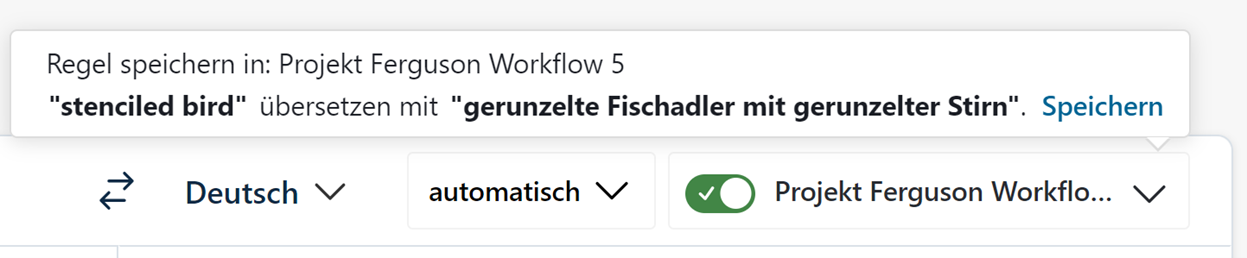
Außerdem besteht unter DeepL bei diesem Schritt die Möglichkeit, das Glossar zu erweitern beziehungsweise zu ergänzen, indem Begriffe im übersetzten Text markiert und entsprechend den Vorschlägen geändert werden. Für diese Änderungen wird vom Programm nachgefragt, ob das so ins Glossar übernommen werden soll.
Das funktioniert in der Praxis im Prinzip gut, technisch ist es jedoch noch nicht ganz ausgereift, denn wenn, wie bei der Textarbeit durchaus üblich, Verschiedenes an unterschiedlichen Stellen im Satz ausprobiert wird, steigt diese Funktion aus und macht unsinnige Vorschläge.
Unangenehm fällt bei der Überarbeitung im Tool auf, dass die Textarbeit streng strukturiert erfolgen muss, immer von oben nach unten. Ändert man zum Beispiel erst in Zeile zwölf etwas und geht dann zu Zeile drei zurück, um dort Änderungen vorzunehmen, so wird das weiter unten Geänderte wieder in den Ursprungszustand zurückversetzt, was kontraproduktiv ist und bei der Überarbeitung aufhält.
Kleinere Tippfehler im Original: »I pivot dangerously on one thin heel at take a smaller, quicker step …« stellen hingegen kein Problem für die Software dar.
Überarbeitung des Zieltextes in MS Word (Office 365)
Um der oben erwähnten Instabilität bei Änderungen vorzubeugen, wurde dazu übergegangen, das Ergebnis der Überarbeitung absatzweise im Textverarbeitungsprogramm zwischenzuspeichern und nach jeder Änderung erneut zu sichern. Das erwies sich als ziemlich zeitaufwendig, aber zielführend.
Nachdem der komplette Zieltext in Word eingefügt worden war, wurden weitere Variationen im Satzbau vorgenommen und als treffender erachtete Begriffe eingefügt, die nicht als Auswahlmöglichkeit in DeepL gelistet waren. Darüber hinaus wurden Wortwiederholungen ausgemerzt und weitere stilistische Nachjustierungen durchgeführt.
Erst bei diesem Schritt konnte die Umrechnung der Maßeinheit »Fuß« in »Meter« erfolgen.
Weiterhin musste bei der Zeichensetzung der wörtlichen Rede korrigierend eingegriffen werden, da hier vom Tool die Zeichensetzung des Originaltextes übernommen wurde.
Das Ergebnis ist als vorläufig endgültig zu betrachten, da der gewählte Textausschnitt zu klein ist, um die Übersetzung im größeren Rahmen des Gesamttextes zu beurteilen.
Fazit
Schon bei der Übersetzung dieses kurzen Ausschnitts mit DeepL zeigt sich, wie beeindruckend gut die maschinengestützte Übersetzung (MÜ) funktioniert, denn herausgekommen ist ein flüssiger Text, und das bei einer belletristischen Vorlage, bei der es ja auch auf einen flüssigen und eingängigen Erzählstil ankommt.
Bei Texten wie dem hier verwendeten lohnt sich der zusätzliche Zeitaufwand kaum, vorab ein Glossar zu erstellen, zumal das im System vorhandene Vokabular für zeitgenössische Unterhaltungsliteratur ausreichend breit aufgestellt ist. Für Romane mit Handlung in der Vergangenheit mag ein Glossar sinnvoll sein.
Die vom Tool vorgeschlagenen Variationen zu Wortwahl und Wortstellung auf Satz- und Satzgliedebene sind eine echte Hilfe auf dem Weg zu einem gut lesbaren Zieltext.
An und für sich ist der Ausgangstext aufgrund der sprachlichen Dichte und Komplexität nicht ideal für die Erprobung von MÜ geeignet. Dieser Text will auf Teufel komm raus anspruchsvoll sein, und sei es mit dem Holzhammer.
Verbesserungs- und Weiterentwicklungsbedarf besteht natürlich trotz des unterm Strich beeindruckenden Ergebnisses: Die MÜ scheint sich sehr eng am Ausgangstext zu orientieren, was sich vor allem bei der Syntax im Zieltext zeigt. Die für das Deutsche typischen Komposita verwendet DeepL nicht, sondern bevorzugt Attribute. Komplexere Satzgliedkonstruktionen sind ebenso problematisch wie die Vermeidung von Wortwiederholungen, auch wenn sich die teilweise anhand der automatisierten Vorschläge im Tool ausmerzen lassen.
Auf Basis neuronaler Netzwerke arbeitende Übersetzungsprogramme werden immer besser, daher liegt die Zukunft auch literarischer Übersetzungen zumindest im Bereich Unterhaltungsliteratur eindeutig in automatisierten Tools. Die dabei entstandenen Texte bedürfen jedoch immer einer gründlichen (menschlichen) Nachbearbeitung, sowohl in Bezug auf den Erzählstil als auch in Bezug auf Genauigkeit. Eine Überprüfung der im Text genannten Fakten auf Richtigkeit kann das Programm nicht leisten.
Review
von Heike Reissig
Für die Peer Review erhielt ich folgende Unterlagen:
- Originaltext auf Englisch (Ausschnitt aus dem Roman Meet Me in the Margins von Melissa Ferguson)
- Zwischenfassung einer mit DeepL vorübersetzten und dann innerhalb von DeepL nachbearbeiteten Übersetzung
- finale, außerhalb von DeepL in Word weiterbearbeitete Fassung der Übersetzung
- Reflexion der bearbeitenden Person, die das Post-Editing durchführte
Meine Aufgabe für das Peer Review bestand darin, auf folgende Fragen einzugehen:
- Was fällt auf?
- Wie ist das Leseerlebnis?
- Welche Erkenntnisse über diesen spezifischen Übersetzungsprozess bietet der Reflexionstext außerdem?
- Decken sich die Erfahrungen der Übersetzerin mit deinen eigenen?
Meine Beobachtungen
Ich kann nicht beurteilen, welche Qualität die unbearbeitete maschinelle Übersetzung von DeepL hatte, da ich als erste Übersetzung eine Zwischenfassung bekam, die bereits von einem Menschen innerhalb von DeepL editiert worden war.
An der ersten editierten Zwischenfassung fällt mir auf, dass sie trotz Bearbeitung noch immer eine große Nähe zur Syntax des Originals und eine recht ausgeprägte Wörtlichkeit aufweist. Viele Passagen der Übersetzung lesen sich zudem seltsam leblos, sie wirken umständlich formuliert und es fehlt der sprühende Funke, der Witz. In der finalen post-editierten Fassung, die außerhalb von DeepL in Word weiterbearbeitet wurde, wurden in fast jedem Satz syntaktische Verschiebungen und/oder idiomatische Anpassungen vorgenommen. Der Bearbeitungsaufwand war also hoch. Trotzdem finde ich, dass die finale post-editierte Fassung noch immer zu wörtlich und seltsam hölzern klingt. Ein Beispiel:
Original:
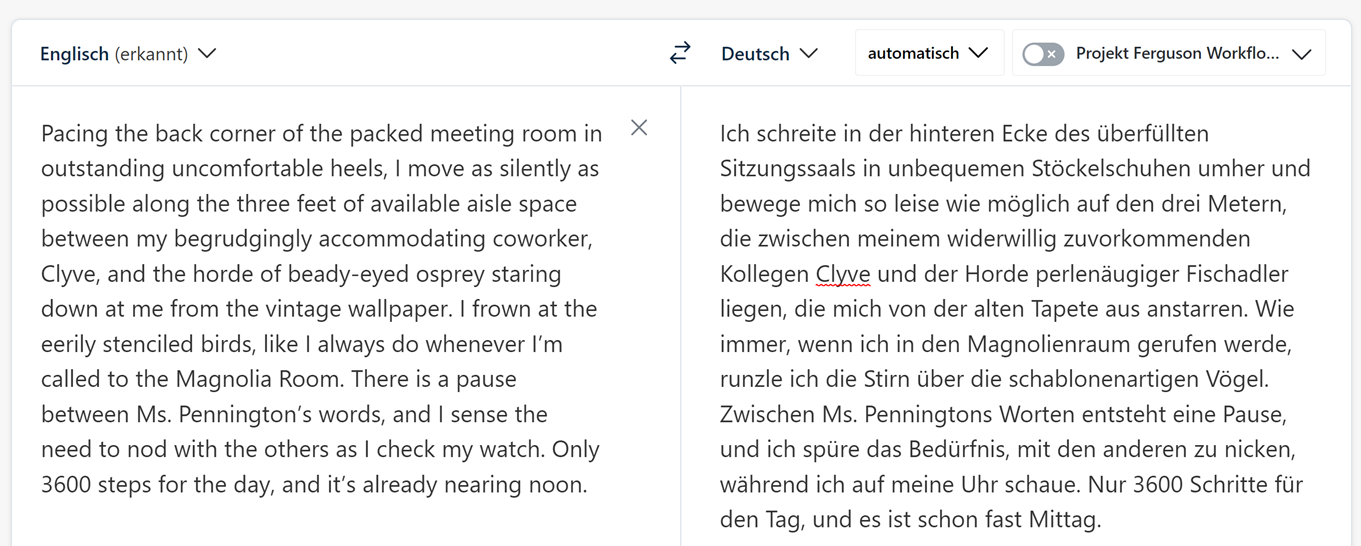
Pacing the back corner of the packed meeting room in outstanding uncomfortable heels, I move as silently as possible along the three feet of available aisle space between my begrudgingly accommodating coworker, Clyve, and the horde of beady-eyed osprey staring down at me from the vintage wallpaper. I frown at the eerily stenciled birds, like I always do whenever I’m called to the Magnolia Room. There is a pause between Ms. Pennington’s words, and I sense the need to nod with the others as I check my watch. Only 3600 steps for the day, and it’s already nearing noon.
Finale post-editierte Fassung:
In bemerkenswert unbequemen Stöckelschuhen gehe ich in der hinteren Ecke des überfüllten Sitzungssaals auf und ab und bewege mich so leise wie möglich auf dem knappen Meter freier Platz zwischen meinem widerstrebend zuvorkommenden Kollegen Clyve und der Horde knopfäugiger Fischadler, die mich von der altmodischen Tapete anstarren. Mit gerunzelter Stirn betrachte ich die unheimlich schablonenhaften Vögel, wie ich es immer tue, wenn ich den Magnolia-Raum gerufen werde. Zwischen Ms. Penningstons Worten entsteht eine Pause, und ich verspüre das Bedürfnis, gemeinsam mit den anderen zu nicken, während ich auf meine Uhr schaue. Nur 3600 Schritte für den Tag, und es ist schon fast Mittag.
Inhaltlich kann ich zwar folgen, doch ich stolpere beim Lesen über den hölzernen Grundton. Für eine flüssigere Lesbarkeit wäre meiner Ansicht nach ein freierer Ansatz nötig. »Only 3600 steps for the day« beispielsweise bezieht sich darauf, dass die Ich-Erzählerin eine Uhr mit Schrittzähler-App verwendet; mit »steps for the day« ist das tägliche Schrittpensum gemeint. Das wird meines Erachtens nicht deutlich genug.
Alternativvorschlag zur Annäherung an eine freiere, lebendiger wirkende Version:
In der hinteren Ecke des überfüllten Sitzungssaals laufe ich auf meinen höllisch unbequemen Highheels so leise wie möglich den schmalen Gang zwischen meinem widerwillig Platz machenden Kollegen Clyve und der Horde knopfäugiger Fischadler auf und ab, die von der altmodischen Tapete auf mich hinabstarren. Stirnrunzelnd betrachte ich die gruselig schablonenhaften Vögel, wie jedes Mal, wenn ich in den Magnolia-Saal zitiert werde. Als zwischen Ms. Penningtons Worten eine kurze Pause entsteht, nicke ich eifrig wie die anderen und schaue kurz auf meine Uhr. 3.600 Schritte Tagespensum, und es ist schon fast Mittag.
Manche übersetzte Passagen enthielten sprachliche und inhaltliche Fehler. Im folgenden Beispiel wurde »the most curated« mit »die kuratiertesten« übersetzt; das Wort existiert im Deutschen nicht. »My latest edit« wurde mit »mein neuestes Werk« übersetzt, doch die Ich-Erzählerin, eine Verlagsmitarbeiterin, hat das Werk gar nicht selbst geschrieben, sie lektoriert es nur. Für den Begriff »commercial fiction« gibt es im Deutschen statt »kommerzielle Belletristik« den Begriff »Unterhaltungsliteratur«. Das im Englischen relativ bekannte Fremdwort »epistemophiliac« wurde mit »Episthemophile« übersetzt; der Begriff war mir unbekannt, also recherchierte ich ihn, konnte ihn jedoch nicht finden. »Epistemophilia« bezieht sich auf den Freudschen »Wissenstrieb« bzw. »Wissensdurst«; demzufolge wäre ein »epistemophiliac« ein »Wissendurstiger«, was jedoch anders als im Original kein Fremdwort ist. Hier böte sich eine völlig freie Übersetzung an, um den Witz mit einem auch bei uns bekannten Fremdwort nachzubilden – eine Idee, auf die DeepL nie käme.
Original:
«Unlike other houses lining the grocery-store shelves with”—her nose wrinkles, as though she can barely handle spitting out the words—«commercial fiction as quickly as they can, Pennington works tirelessly to produce only the most curated, thoroughly vetted manuscripts worth printing on the page. Only the most curated, vetted manuscripts we believe the world needs to read.” I raise a brow as I slash another word. It’s a nice sentiment, but I don’t know if the whole world needed to have in their possession my latest edit: The Incredible World of Words: An Epistemophiliac’s Guide.
Finale post-editierte Fassung:
»Im Gegensatz zu anderen Verlagen, die die Regale in den Supermärkten mit« – sie rümpft die Nase, als koste es sie Überwindung, die Worte überhaupt über die Lippen zu bringen – »kommerzieller Belletristik fluten, arbeitet Pennington unermüdlich daran, nur die kuratiertesten, am gründlichsten geprüften Manuskripte zu veröffentlichen, die es verdienen, gedruckt zu werden. Nur die kuratiertesten, am besten geprüften Manuskripte, von denen wir glauben, dass die Welt sie lesen sollte.« Ich ziehe eine Augenbraue hoch, während ich ein weiteres Wort streiche. Das ist eine bewundernswerte Einstellung, aber ich weiß nicht, ob die Welt mein neuestes Werk unbedingt braucht: Die unglaubliche Welt der Wörter – Ein Leitfaden für Epistemophile.
Alternativvorschlag zur Annäherung an eine freiere, lebendiger wirkende Version:
»Im Gegensatz zu anderen Verlagen, die die Supermarktregale im Akkord mit« – sie rümpft die Nase, als brächte sie die Worte kaum über die Lippen – »Unterhaltungsliteratur füllen, hat Pennington sich der Mission verschrieben, nur sorgfältig ausgewählte Manuskripte zu veröffentlichen, die es wert sind, gedruckt zu werden. Nur Werke, die die Welt unbedingt lesen sollte.« Ich ziehe die Braue hoch und streiche ein weiteres Wort. Die Einstellung imponiert mir, doch ich bezweifle, dass die Welt das Werk, das ich gerade lektoriere, wirklich braucht: Die Geheimnisse der Gummierung – Ein Wegweiser für Philatelisten.
Ein weiteres Beispiel illustriert unter anderem, wie wichtig Recherchen sind, um einen Text korrekt zu übersetzen.
Original:
Pennington is a sailboat. A beautiful Pen Duick regatta cutter whose owner slides his hand over the rosewood, mahogany, teak, and other exotic tropical woods of the hull with pride while watching the vast white sail overhead billow in the sea-salt breeze. Intricately detailed. Unlike any other. But still just a bobbing speck compared to the ocean liner charging through.
Finale post-editierte Fassung:
Pennington ist ein Segelboot. Ein wunderschöner Regatta-Cutter von Pen Duick, dessen Besitzer mit Stolz über die Palisander-, Mahagoni-, Teak- und anderen exotischen Tropenhölzer des Rumpfes streicht, während sich das riesige weiße Segel über ihm in der salzigen Meeresbrise bläht. Voller liebevoller Details. Anders als alle anderen. Aber dennoch nur ein dümpelnder Kahn im Vergleich zu den Ozeanriesen, die durch die Wellen pflügen.
Alternativvorschlag zur Annäherung an eine freiere, lebendiger wirkende Version:
Pennington ist ein Segelschiff, eine prächtige Pen Duick, deren Besitzer stolz über das Rosenholz und Mahagoni des Rumpfes streicht, während er das große weiße Segel betrachtet, das sich über ihm in der Meeresbrise bauscht. Eine Regatta-Yacht voller außergewöhnlicher Details. Einzigartig. Und doch nur eine dümpelnde Nussschale im Vergleich zu einem wellenpflügenden Ozeanriesen.
DeepL weiß nicht, was der Begriff »Pen Duick« bedeutet, und übersetzt daher falsch. Bei Recherchen stößt man auf die Information, dass es sich um einen besonderen Typ von Segelyachten handelt, die von Éric Tabarly erbaut wurden, einem der innovativsten Konstrukteure von Regattayachten des 20. Jahrhunderts, siehe https://de.wikipedia.org/wiki/%C3%89ric_Tabarly . Weitere Probleme bestehen in der fehlerhaften Übersetzung des Begriffs »regatta cutter« oder darin, dass aus einem einzigen »ocean liner« mehrere gemacht werden. Um eine bessere Lesbarkeit zu erreichen, sollte die ganze Passage meiner Ansicht nach etwas freier übersetzt werden. An manchen Stellen, u. a. bei längeren Aufzählungen, kann es legitim sein, den Text zu straffen oder zu kürzen, ohne dass dadurch etwas verloren geht.
An dieser Post-Editing-Fassung wird meines Erachtens ein grundsätzliches Problem maschineller Übersetzungen deutlich. Mein Eindruck ist, dass es der bearbeitenden Person ähnlich wie mir selbst bei meinem Experiment erging: Ihr Fokus wurde vom Original, wo er eigentlich stets sein sollte, weggelenkt, und zwar auf die maschinelle Übersetzung, die auf verschiedenen Ebenen fehlerhaft war und optimiert werden sollte. Die bearbeitende Person versuchte, dieser Aufgabe so gut es ging gerecht zu werden, blieb jedoch zwangsläufig der Struktur der maschinellen Übersetzung verhaftet – zuerst, als sie innerhalb von DeepL mit Vorschlägen von DeepL editierte, doch auch später, als sie die maschinelle Übersetzung außerhalb von DeepL abschließend bearbeitete. Aus der Reflexion der bearbeitenden Person geht hervor, dass das Editing innerhalb von DeepL umständlich und zeitaufwändig war; ähnlich habe ich es auch erlebt. Man ist so mit der Bedienoberfläche des Programms beschäftigt, dass man dazu verleitet wird, die maschinelle Übersetzung ohne ausreichenden Blick aufs Original zu verbessern und Fehler der maschinellen Übersetzung zu übersehen.
Das Fazit, dass die maschinengestützte Übersetzung beeindruckend gut funktioniert, teile ich nicht. Meiner Ansicht nach ist das Ergebnis nur oberflächlich betrachtet flüssig und gut lesbar. Die Ansicht, dass die Zukunft von Übersetzungen im Bereich Unterhaltungsliteratur eindeutig bei automatisierten Tools liege, teile ich ebenfalls nicht. Dieses Post-Editing-Experiment hat mir ebenso wie mein eigenes gezeigt, dass die maschinelle Übersetzung dem komplexen schöpferischen Prozess des menschlichen Übersetzens nicht gerecht werden kann, und dass sie der menschlichen Nachbearbeitung obendrein ein Korsett aufzwingt, das sich nur schwer ablegen lässt. All das geht letztendlich zu Lasten der Qualität und führt zu einem Endergebnis, das weder Zeit spart noch dem Original gerecht wird.
Bild: Виталий Сова