
Maschinelle Übersetzung – ein Blick unter die Haube
Wie funktioniert eigentlich Maschinelle Übersetzung? Und wie gut können moderne KI-Systeme, wie z. B. ChatGPT, Literatur übersetzen? Wird MÜ den Menschen bald ersetzen? Dr. Steffen Eger, der zu Natural Language Processing forscht, bringt Licht ins Dunkel.
Die Anfänge der maschinellen Übersetzung
Das »Georgetown-IBM-Experiment« von 1954, das als Beginn der Maschinellen Übersetzung (MÜ) angesehen werden kann und sich mit der Übersetzung vom Russischen ins Englische befasste, trug maßgeblich zur Popularität von MÜ bei: auf dem Höhepunkt des Kalten Krieges war schnelle Übersetzung von Russisch nach Englisch zunehmend wichtig. Der ALPAC-Report von 1966, ein Bericht von sieben US-amerikanischen Wissenschaftlern zur Lage der Computerlinguistik, kam allerdings zum Schluss, dass MÜ zu teuer, zu ungenau und zu langsam sei. Dies fällt in den größeren historischen Kontext eines zeitgenössischen »KI-Winters«, in dem Methoden und Ergebnisse der Künstlichen Intelligenz in Forschung und Öffentlichkeit negativ bewertet wurden.
Die folgenden Jahre brachten vor allem konzeptuelle Ideen hervor, zum Beispiel dass MÜ die Stufen linguistischer Analyse zu befolgen habe; dies wird in modernen MÜ-Systemen, die zumeist rein-datenbasiert operieren, allerdings kaum noch berücksichtigt.
Die sogenannten »IBM-Artikel« von Brown et al. [1] in den 1990ern bedeuten den Beginn des modernen Bottom-up-Konzepts von MÜ: Ausgehend von parallelen Daten – also Tausenden oder Millionen von Beispiel-Übersetzungen – werden statistische Modelle »trainiert«, die von einer Sprache in die andere übersetzen. Alle modernen MÜ-Systeme basieren dabei auf Prinzipien des Maschinellen Lernens.
Maschinelles Lernen
Maschinelles Lernen (ML) beschäftigt sich mit der Induktion von Systemen anhand konkreter Beispiele (Daten), so dass die Systeme auf ähnlich gelagerte Fälle verallgemeinern können. So könnte ein System für die Aufgabe der Sentimentanalyse trainiert werden, das heißt zur Erkennung von positiven, negativen, oder neutralen Haltungen in Texten, wobei spezifische händisch annotierte positive/negative/neutrale Texte als Trainingsbeispiele dienen. MÜ ist im Grunde »nur« ein Spezialfall von ML, bei dem die Beispiele Paare von Texten oder Sätzen sind: Der Trainingsinput ist in der Ausgangssprache und der Trainingsoutput in der Zielsprache geschrieben.
ML-Modelle haben zwei Kernbestandteile: eine Architektur und eine Repräsentation des Inputs (und Outputs). Widmen wir uns zunächst den Repräsentationen.
Vektorrepräsentation von Wörtern
Damit ein Computer Text verarbeiten kann, werden Wörter numerisch dargestellt. Die Herausforderung besteht darin, in dieser Darstellung möglichst viele Eigenschaften der Wörter in ihrem jeweiligen Kontext zu repräsentieren.
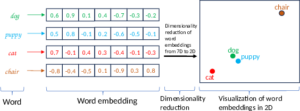
In den Jahren 2013–2014 gelang dem Informatiker Tomáš Mikolov der empirische Beleg, dass Repräsentation von Wörtern, die sich durch die Vorhersage des sprachlichen Kontexts mittels sogenannter neuronaler Netzwerke ergeben, besonders gut sind: Diese word embeddings repräsentieren zum Beispiel intuitiv bedeutungsähnliche Wörter durch ähnliche Vektoren, das heißt, sie modellieren Semantik besonders zuverlässig. Solche Vektoren können visuell dargestellt werden – allerdings nur in einem zwei- oder dreidimensionalen Raum.
Architektur: Encoder-Decoder-Modelle
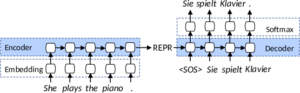
Kommen wir nun zum zweiten wesentlichen Aspekt von ML-Modellen: ihrer Architektur. Modelle zur Textgenerierung sind oft Encoder-Decoder-Modelle, die einen gesamten Eingabetext zunächst via Vektorrepräsentation enkodieren und basierend auf dieser Kodierung einen Output erzeugen (dekodieren), also im Fall von MÜ die Übersetzung. Zugrunde lagen dabei in der jüngeren Vergangenheit (seit 2014) oft Rekurrente Neuronale Netzwerke (RNN). Zunächst werden die Wörter des Inputs als Embeddings dargestellt und in ein RNN eingespeist, das nun schrittweise eine numerische Repräsentation des gesamten Satzes bis zum jeweiligen Wort bildet und dabei alle vorangegangenen Wörter berücksichtigt. In der Repräsentation des letzten Wortes (in der Grafik unten als »REPR« symbolisiert) steckt somit die Kodierung für den gesamten Satz. Daraus wird die Übersetzung Wort für Wort erzeugt.
Encoder-Decoder-Modelle sind bis heute der Standardansatz für MÜ. Verändert hat sich hauptsächlich deren konkrete Umsetzung (z. B. mittels RNNs vs. Transformern; Letztere sind der aktuelle Stand der Technik).
Die Transformer-Architektur basiert dabei auf dem Paper »Attention Is All You Need« von Vaswani et al. [2]. Transformer bauen auf dem sogenannten Attention-Mechanismus auf: Hier kann das Modell selbst lernen, bestimmten Teilen des Inputs besondere Aufmerksamkeit (eben attention) zu widmen. Mindestens ebenso wichtig wie attention ist allerdings, dass Transformer-Architekturen, anders als RNN, nicht-rekurrent sind. Man kann sie daher einfacher parallelisieren und dadurch effizienter trainieren. Sie können dann auf viel größeren Datenmengen trainiert werden, was für das pre-training bedeutsam ist. Alle aktuellen Modelle wie BERT oder ChatGPT, das unten noch kurz diskutiert wird, basieren auf Transformer-Architekturen.
Beschränkungen
Trotz bedeutender Fortschritte weisen MÜ-Modelle eine Reihe von Defiziten auf (insbesondere vor Ende 2022 und dem Aufkommen einer neuen Generation von Large Language Models (LLMs) wie ChatGPT). Diese umfassen Probleme mit längeren Texten (in denen Phänomene wie Koreferenz, Kohärenz, etc. wichtig sind), mit distanteren Sprachpaaren, mit Übersetzungen aus Sprachen ohne Genusmarkierungen in Sprachen mit Genusmarkierungen, etc. MÜ-Systeme sind auch ganz explizit von ihren Trainingsdaten abhängig: Je nach Alter und Entstehungskontext der Trainingsdaten kann der Output »älter und männlicher« klingen [3]. Allgemeiner können MÜ und andere KI-Systeme soziale »biases« aus ihren Trainingsdaten wiedergeben und sogar verstärken. Eine weitere grundsätzliche Schwierigkeit von MÜ besteht in ihrer Evaluation; ein Forschungsstrang ([4], [5], [6]) kommt zu dem Ergebnis, dass MÜ-Systeme oft mit unzureichenden automatischen Metriken (z. B. die populären, aber ungeeigneten BLEU-Metriken [7]) bewertet werden; das bedeutet, ihre Qualität wird unter- oder überschätzt. Auch menschliche Evaluation ist problematisch, z. B. hinsichtlich der Kompetenz der Evaluierenden, die oft ungeschulte Hilfskräfte sind. Wie schon erwähnt, kam seit Ende 2022 mit ChatGPT eine neue Klasse von LLMs auf, die einige dieser Probleme beheben, insbesondere hinsichtlich »Flüssigkeit« (fluency) und Kohärenz. Dies stellt ein extrem spannendes Forschungsfeld für die kommenden Monate und Jahre dar – siehe unten zu aktuell erschienenen Arbeiten und deren Schwächen und Stärken. Aufgrund seiner Prominenz soll ChatGPT im Folgenden kurz beschrieben werden.
Zwischenspiel: GPT und ChatGPT
Die GPT-Modellserie umfasst zunächst Modelle zur Textgenerierung, das heißt, man kann mit ihnen automatisch Texte erzeugen. Diese Modelle (GPT-2, GPT-3, GPT-3.5, ChatGPT, GPT-4 etc.) unterscheiden sich in ihrer Größe und den zugrundeliegenden Trainingsdaten.
Je größer die Architektur und das Trainingskorpus, desto besser sind die Modelle. ChatGPT unterscheidet sich von den Vorgängermodellen (hauptsächlich) dadurch, dass es zusätzlich auf menschlichen Interaktionen optimiert wurde. Die GPT-Modelle können auch übersetzen, obwohl ihre Trainingsdaten nicht systematisch (sondern nur zufällig) Übersetzungen enthalten – diese Signale werden indirekt mitgelernt. Zu den Übersetzungsfähigkeiten von ChatGPT gibt es bereits einige Arbeiten, von denen hier zwei erwähnt werden sollen:
Das Paper »Is ChatGPT A Good Translator? Yes With GPT-4 As The Engine« (von Januar 2023, bisher noch nicht publiziert) stellt fest, dass ChatGPT so gut wie kommerzielle Übersetzungssysteme auf Sprachpaaren wie Deutsch-Englisch ist (high-resource languages), aber schlechter auf low-resource-Sprachpaaren funktioniert. Verwendet man allerdings GPT-4 im Hintergrund (ChatGPT basiert ursprünglich auf GPT-3.5), dann ist ChatGPT »gleichauf« mit kommerziellen Übersetzungsmodellen. Das Paper »Towards Making the Most of ChatGPT for Machine Translation« (von März 2023, bisher noch nicht publiziert) untersucht, wie sich verschiedene Strategien (z.B. die Auswahl des sog. Prompts, also der Übersetzungsanfrage beim Modell) auswirken. Ein negatives Ergebnis dabei ist, dass ChatGPT bei Sprachpaaren ohne Englisch mehr halluziniert, also mehr Falschinformation generiert.
Aktueller Forschungsstand zur maschinellen Literaturübersetzung
Literaturübersetzung ist ein in der gegenwärtigen Forschung zu Natural Language Processing (NLP) sehr wenig beachtetes Thema. Einerseits gibt es wenig frei verfügbare parallele Datensätze zu Literatur, auf denen trainiert werden könnte. Andererseits scheint insgesamt weniger Interesse (sowohl gesamtgesellschaftlich als auch in der Forschung) an maschineller Literaturübersetzung zu bestehen. Zudem gestaltet sich MÜ von Literatur aus verschiedenen Gründen besonders schwierig. Im Folgenden werden drei aktuelle Studien zu dem Thema besprochen.
Das Paper von Chakrabarty et al. [8] beschäftigt sich mit der Übersetzung von Gedichten und konstatiert die Schwierigkeit des Problems, da solche Übersetzungen nicht nur den Inhalt, sondern auch den Stil des Ursprungsgedichts erhalten müssen. Insgesamt stecke automatische Gedichtübersetzung in den Kinderschuhen, auch weil es kaum parallele Daten zum Trainieren gebe. Hier leistet das Paper einen wichtigen Beitrag, indem es solche für mehrere Sprachen (Deutsch, Russisch etc., jeweils mit Übersetzungen ins Englische) zur Verfügung stellt – beinahe 200.000 Zeilen, die aus dem Internet extrahiert wurden. Andererseits weist das Paper selbst auch dezidierte Schwächen auf: So konzipiert es zum Beispiel Gedichtübersetzung auf Zeilenebene statt auf Gedichtebene, und auch die Qualität der Daten selbst ist unklar.
Das Paper von Thai et al. [9] stellt zunächst heraus, dass Übersetzung von Literatur viel schwieriger sei als »Standard-MÜ«, da Literaturübersetzung semantischer und kritischer Interpretation sowie »Wirkungsäquivalenz« bedürfe. Außerdem beinhalte Literatur oft eine komplexe Textstruktur, was eine große Herausforderung für die typischerweise auf Satzebene operierenden MÜ-Systeme bedeute. Das Paper zeigt, dass menschliche Evaluation durch professionelle Übersetzer menschliche Übersetzungen deutlich gegenüber automatischen präferiere, wohingegen automatische Metriken den MÜ-Output bevorzugen würden – das zeigt, dass sowohl die automatischen Übersetzungssysteme als auch die automatischen Evaluationsmetriken klare Schwächen aufweisen. Die Hauptprobleme der MÜ-Systeme beziehen sich laut der Fehleranalyse des Papers auf allzu wörtliche Übersetzungen sowie Fehler auf Textebene inklusive Koreferenz und Pronomenkonsistenz. Dieses Paper stellt ebenfalls einen neuen Datensatz zur Verfügung, der 121.000 Absätze aus 118 Romanen umfasst, die ursprünglich in einer von 19 nicht-englischen Sprachen verfasst wurden.
Das Paper von meinen Kolleg*innen Ran Zhang, Jihed Ouni und mir selbst [10] beschäftigt sich mit der zusammenfassenden Übersetzung historischer fiktionaler Texte in einer anderen modernen Sprache. Diese Aufgabe besteht konzeptuell aus drei Schritten: Zusammenfassung, Übersetzung und historische Sprach-Normalisierung. Das Paper konstruiert zunächst einen Datensatz von Romanen (hauptsächlich Märchen) des 19. Jahrhunderts, deren Zusammenfassungen aus Wikipedia stammen. Auf Basis dieser Daten werden verschiedene populäre Modelle trainiert, welche allerdings höchstens durchschnittliche Ergebnisse erzielen (sowohl nach menschlicher als auch automatischer Evaluierung), während das populäre ChatGPT-Modell eindeutig besser abschneidet. Allerdings sei hervorgehoben, dass ChatGPT die meisten Geschichten (und auch mögliche Zusammenfassungen) »kennt«, da es einen großen Teil des Internets bereits als Trainingsdaten »gesehen« hat. Die Ergebnisse von ChatGPT und neueren LLMs weisen insgesamt auf ein bedeutsames Entwicklungspotenzial für MÜ hin, auch wenn sie in unserem Fall nicht von professionellen Evaluatoren bewertet wurden.
Zusammenfassend lässt sich feststellen, dass MÜ von Literatur aktuell noch in den Kinderschuhen steckt. Es fehlt(e) vor allem an parallelen Daten und an mächtigeren ML-Systemen, die längere Kontexte berücksichtigen können. Aktuell zeigt sich in beiden Problemfeldern erheblicher Fortschritt. Im Zusammenspiel mit Literaturübersetzenden könnte sich daher in den nächsten Jahren ein Durchbruch ergeben. Auch wenn dies spekulativ ist, stützen die jüngsten Entwicklungen solche optimistischen Visionen.
- Brown et al. A Statistical Approach to Machine Translation, Computational Linguistics, 1990 ↑
- Vaswani et al., “Attention is All you Need”, NeurIPS 2017↑
- Hovy et al. “You Sound Just Like Your Father” Commercial Machine Translation Systems Include Stylistic Biases, ACL 2020 ↑
- Marie et al., Scientific Credibility of Machine Translation Research: A Meta-Evaluation of 769 Papers, ACL 2021 ↑
- Mathur et al., Tangled up in BLEU: Reevaluating the Evaluation of Automatic Machine Translation Evaluation Metrics, ACL 2020 ↑
- Chen and Eger, MENLI: Robust Evaluation Metrics from Natural Language Inference, TACL 2023 ↑
- Papieni et al., BLEU: a Method for Automatic Evaluation of Machine Translation, ACL 2002 ↑
- Chakrabarty et al. Don’t Go Far Off: An Empirical Study on Neural Poetry Translation, EMNLP 2021 ↑
- Thai et al., Exploring Document-Level Literary Machine Translation with Parallel Paragraphs from World Literature, EMNLP 2022 ↑
- Zhang, Ouni, Eger. Cross-lingual Cross-temporal Summarization: Dataset, Models, Evaluation, 2023, Arxiv Preprint ↑
Dr. Steffen Eger forscht im Bereich Natürliche Sprachverarbeitung (NLP, Computerlinguistik) und ist Heisenberg-Gruppenleiter an der Universität Mannheim. Er forscht mit seinem Team zu interdisziplinären Fragestellungen an der Schnittstelle von Künstlicher Intelligenz, natürlicher Sprachverarbeitung, Digitalen Geisteswissenschaften und Sozialwissenschaften. Unter anderem befasst er sich mit der Entwicklung von hoch-qualitativen Evaluationsmetriken für Maschinelle Übersetzung, u.a. gefördert durch das Bundesministerium für Bildung und Forschung (BMBF) in einer KI-Nachwuchsgruppe (Projektname: »Metrics4NLG«) mit fast einer Million Euro Budget.
Beitragsbild: Gorodenkoff