
Gebt uns bessere Übersetzungssoftware!
Daniel Landes erkundet den Einsatz von DeepL im CAT-Tool memoQ. Was er sich als Übersetzer von der weiteren Entwicklung der Technik wünscht, schreibt er in diesem Text.
Im Rahmen des Experiments von Kollektive Intelligenz setze ich mich mit der Übersetzung einer ca. 800 Wörter langen Passage aus Melissa Fergusons Roman Meet Me in the Margins unter Zuhilfenahme des CAT-Tools memoQ sowie des Plug-ins von DeepL auseinander.
Vorbereitung: Das Zusammenspiel der Technik
Da ich fast täglich mit memoQ arbeite, einem Tool für computergestützte Übersetzung, kann ich innerhalb weniger Minuten ein neues Projekt aufsetzen und eine Termdatenbank sowie ein Translation Memory anhängen. Auch der Import der Word-Datei geht reibungslos vonstatten. Das CAT-Tool zerlegt den Ausgangstext in Segmente, hier lauter jeweils in sich abgeschlossene Sätze, und zeigt sie mir in einer Spalte an. Die integrierte Funktion zur Termextraktion kenne ich noch nicht, dank der Webhilfe finde ich mich jedoch schnell zurecht und kann relevante Begriffe für die Termdatenbank identifizieren. Diese Funktion erscheint mir unglaublich nützlich und ich habe vor, sie für zukünftige Projekte zu nutzen. Da die zu bearbeitende Textpassage überschaubar ist, hält sich der Nutzen in diesem konkreten Fall aber in Grenzen.
Die Aktivierung des Plug-ins für maschinelle Übersetzung (MÜ) von DeepL in der Umgebung von memoQ stellt sich als komplizierter heraus. Der Authentifizierungsschlüssel wird anfangs nicht erkannt, und erst nach mehreren Neustarts und der Löschung des bestehenden Profils in der Ressourcenkonsole ist das Setup schließlich erfolgreich abgeschlossen.
Übersetzungsphase: Störgeräusche durch DeepL
Ich entscheide mich dafür, nicht mit der maschinellen Übersetzung vorzuübersetzen, sondern die Vorschläge der MÜ lediglich im Translation-Results-Bereich des Programms anzeigen zu lassen. So kann ich, je nach Qualität des Textes, selbst entscheiden, ob ich mit dem maschinellen Output arbeiten oder lieber komplett selbst übersetzen will.
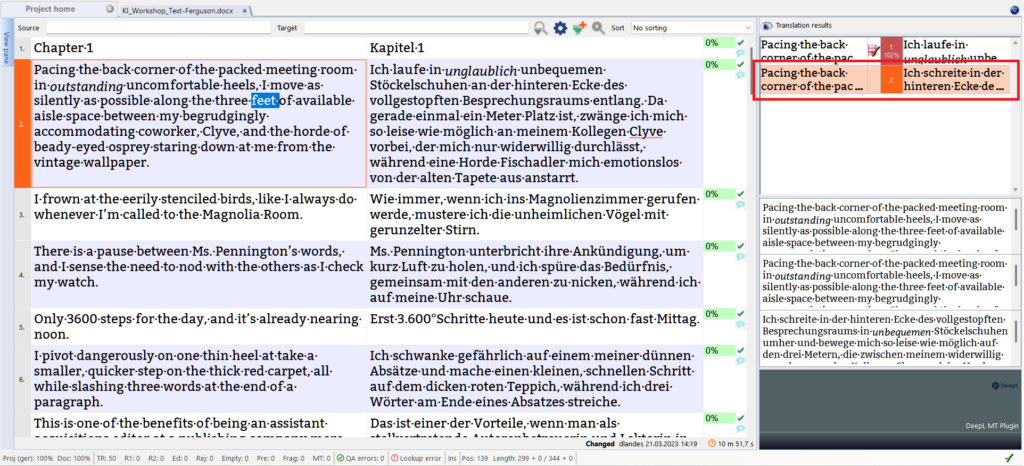
Gleich beim ersten Satz bleibe ich hängen, da der englische Satzbau relativ komplex ist und ich nicht sofort verstehe, wie die Autorin die Szene beschreibt. DeepL kann hier leider auch kein Licht ins Dunkel bringen, da die direkte wörtliche Übertragung ins Deutsche
Ich schreite in der hinteren Ecke des vollgestopften Besprechungsraums in unbequemen Stöckelschuhen umher und bewege mich so leise wie möglich auf den drei Metern, die zwischen meinem widerwillig zuvorkommenden Kollegen Clyve und der Horde perlenäugiger Fischadler liegen, die mich von der alten Tapete aus anstarren.
kein benutzbarer Output ist, obwohl die Algorithmen nicht völlig falsch vorgehen und mir ein paar brauchbare Kürzungen vorschlagen. Allerdings unterschlagen sie auch ein paar Wörter (»outstanding uncomfortable heels« wird zu »unbequeme Stöckelschuhe« und nicht »unglaublich unbequeme Stöckelschuhe«), wodurch meiner Meinung nach die Erzählstimme der Autorin einiges an Persönlichkeit einbüßt.
Da ich im ersten Satz festhänge, arbeite ich erst einmal weiter. In den Folgesätzen gibt mir DeepL den hilfreichen Impuls, Haupt- und Nebensatz eines Segments umzudrehen, wodurch die Übersetzung gleich idiomatischer klingt ; allerdings sorgt die KI auch weiterhin mit viel zu wörtlichen Übersetzungen und grundlos unterschlagenen Wörtern (»eerily stenciled birds« wird zu »schablonierte Vögel«) für Stirnrunzeln. Den Algorithmen fehlt das Gespür für die richtige Wortwahl (»beady-eyed ospreys« wird zu »perläugige Fischadler«, ich entscheide mich später für »ausdruckslos starrende Fischadler«) und dafür, welche englischen Wörter zur Verbesserung des deutschen Textes weggelassen werden können.
Die App von DeepL bietet die interessante Funktion, durch einen Klick auf ein Wort, das mir nicht gefällt, eine Liste mit Synonymen oder anderen Wörtern einzublenden, die in die Kollokation passen. Dieses Feature vermisse ich in der CAT-Tool-Oberfläche schmerzlich, da man mit den Wörtern arbeiten muss, für die DeepL sich entschieden hat.
Um passendere Übersetzungsvorschläge zu erhalten, kopiere ich also einige der Sätze in die DeepL-App, profitiere von den präsentierten Synonymen und bin schließlich mit den Sätzen zufrieden.
Als ich zum ersten Satz zurückkehre, fällt endlich der Groschen und ich verstehe, was die Autorin mir sagen will. Letztendlich muss ich für meine Übersetzung komplett weggehen vom Ausgangstext und die Szene anders beschreiben, damit sie verständlich wird. Ich frage mich, ob DeepL mich mit seiner direkten Übersetzung bereits in eine bestimmte Richtung geschickt hat und ich deswegen Schwierigkeiten hatte, zu verstehen, was gemeint war.
Während einige Fehler und schiefe Formulierungen sofort ins Auge fallen (»none of the eyes flicker« wird zu »keine Augen flackern«, obwohl eigentlich »niemand mit der Wimper zuckt«), erwische ich mich dabei, wie ich bei manchen Begriffen der Maschine blind vertraue. Erst im Nachhinein fällt mir ein, dass ich die Übersetzung für »Osprey« lieber noch einmal verifizieren sollte, da mir diese Vokabel nicht geläufig ist, anstatt den Vorschlag der KI als der Weisheit letzter Schluss anzusehen.
Andere unbekannte Wörter lassen sich durch den Kontext bestätigen, was dann eine echte Zeitersparnis darstellt, da ich zum Beispiel nicht nachschlagen muss, was mit »pivot« gemeint ist. Außerdem lässt sich DeepL auch von Tippfehlern nicht aus der Ruhe bringen und liefert richtige Ergebnisse. Generell sollte man sich aber nicht zu sehr auf die Maschine verlassen, da sie auch gerne mal danebenlangt (aus »gemeinsam mit den anderen nicken« macht sie zum Beispiel »den anderen zunicken«). Wenn man ein Wort nicht aktiv beherrscht, ist es ratsam, DeepLs Vorschlag mit einem herkömmlichen Wörterbuch zu überprüfen. Ich könnte mir vorstellen, dass in Zukunft hervorragende sprachliche Kompetenzen noch wichtiger werden als heute, da die KI Text auf hohem Niveau produziert und nur wirklich kompetente Menschen Fehler erkennen.
Nachdem ich anfangs etwas willkürlich zwischen Ausgangstext und maschinellem Output gesprungen bin, etabliere ich langsam eine strukturierte Vorgehensweise. Ich lese mir den Ausgangstext durch, erfasse die Bedeutung und lasse mich dann auf den MÜ-Output ein, um ihn in einem ersten Schritt auf inhaltliche Fehler zu prüfen. Sobald ich sicher bin, dass alles in Ordnung ist, mache ich mich daran, den deutschen Text losgelöst vom Ausgangstext auf Hochglanz zu polieren. Bei dieser Vorgehensweise kristallisieren sich schnell zwei Fälle heraus: Der Output bietet einige Formulierungen, mit denen ich arbeiten kann, und lässt sich umschreiben – oder der Output ist unbrauchbar und ich bin schneller, wenn ich von null anfange.
Im Laufe der Arbeit fallen mir vor allem die folgenden Aspekte auf:
- Die MÜ hat oft mit Inkonsistenzen zu kämpfen und schreibt beispielsweise manchmal »Ms.«, manchmal »Frau«.
- Außerdem stellt sie bei der Konvertierung von Maßeinheiten ganz abenteuerliche Rechnungen an und macht aus »3 feet« erst »3 Meter«, im Anschluss dann aus »5 feet« »1,80 Meter«. Glücklicherweise lässt mich der Kontext hellhörig werden, und ich bemühe Google für die korrekte Umrechnung.
- Bei Berufsbezeichnungen, bei denen das Geschlecht nicht klar ist, verwendet DeepL in meinem Beispiel ausschließlich männliche Formen, und auch die KI erspart mir eine langwierigere Recherche zum Begriff »acquisitions editor« nicht, da sie mir lediglich einen wörtlichen Vorschlag ausspuckt.
- Wie bereits erwähnt, ersetzt sie Wörter, die ein gewisses Flair und eine gewisse Persönlichkeit transportieren, oft durch neutralere Ausdrücke – so wird aus »jotting down« mit DeepL einfach »aufschreiben« und nicht »hinkritzeln«, wodurch in meinen Augen Atmosphäre verloren geht.
- Überhaupt ist Atmosphäre ein weiteres Problem: Mich beschleicht das Gefühl, dass DeepL den Text Segment für Segment übersetzt, ohne auf den Gesamtkontext und Fluss zu achten. Anschlüsse sind daher oft holprig, und auch der Mensch, der durch die Segmentierung des CAT-Tools bereits auf Schubladendenken getrimmt wird, wird weiter dazu verleitet, Segmente in Isolation zu betrachten. Das fällt vor allem in der Korrekturphase auf, in der ich die fertige Übersetzung als Ganzes in Word noch einmal durchgehe. Da ich praktisch mit zwei Texten arbeite – einem vor Charme sprühenden Ausgangstext und einem gedämpften, neutralen maschinell übersetzten Text –, fällt es mir auch schwerer, die Erzählstimme der Autorin in meinem Kopf zu hören. Ich empfinde den MÜ-Output hier fast als eine Art Störgeräusch.
Da bei MÜ oft von Effizienzgewinnen gesprochen wird, möchte ich auch erwähnen, dass ich nicht das Gefühl hatte, schneller zu arbeiten als sonst. Kurze simple Sätze lassen sich zwar direkt übernehmen, davon waren in meiner Textpassage aber nicht genügend vorhanden. Ich hatte außerdem den Eindruck, dass das »Umbauen« des maschinellen Outputs genauso viel oder mehr Zeit in Anspruch nimmt als eine komplett eigene Übersetzung. Zudem hatte ich bei diesem Experiment genügend Zeit, um dem Text ein großes Maß an Feinschliff zukommen zu lassen. Ich könnte mir vorstellen, dass ich nach 6 Stunden Arbeit nicht mehr so aufmerksam arbeite.
Korrekturphase: Immer unerlässlich
Nach der Übersetzung in der Benutzeroberfläche des CAT-Tools ist es mir wichtig, in einer Ansicht Korrektur zu lesen, die dem Textfluss zuträglich ist. In memoQ selbst eignet sich dafür das View Pane, das den Text in der ursprünglichen Formatierung anzeigt. Von Vorteil ist hier, dass man per Klick auf einen Satz direkt in das entsprechende Segment springen und Änderungen vornehmen kann. Leider wird der Text recht klein dargestellt, sodass man sich beim Lesen etwas schwer tut. Exportiert man die Übersetzung hingegen als Word-Datei, kann man komfortabel lesen, hat allerdings den doppelten Arbeitsaufwand, wenn man sein Translation Memory aktuell halten und Änderungen in beiden Programmen übernehmen möchte.
Das Korrekturlesen ist ein wichtiger Bestandteil des Übersetzungsprozesses, und das gilt auch für das Post-Editing. Der Korrekturaufwand erschien mir im Vergleich zu einer MÜ-freien Übersetzung weder größer noch kleiner gewesen zu sein. Außerdem beschränken sich Anpassungen auf Feinheiten, gröbere Schnitzer und Fehler sind mir nicht aufgefallen.
Abschließende Gedanken: Zähe Arbeit, irreführende Vorschläge
Ich arbeite sehr gerne mit CAT-Tools und nutze auch die DeepL-App regelmäßig, weil ich die Synonym- und Wörterbuchfunktionen sehr hilfreich finde. Die Arbeit mit dem MÜ-Plug-in in memoQ empfand ich jedoch als etwas zäh, da eben diese Funktionen nicht abrufbar waren.
Bei kurzen Sätzen ohne Interpretationsspielraum lässt sich der maschinelle Output zwar übernehmen, dafür macht es bei komplexeren Sätzen, bei denen die Persönlichkeit der Autorin/Erzählerin transportiert werden soll, deutlich mehr Arbeit, die MÜ umzuschreiben. Auch zum Verständnis von komplexen Sätzen eignet sie sich nur bis zu einem gewissen Grad, da direkte wörtliche Übersetzungen auch auf den Holzweg führen können oder nicht weiterhelfen.
Auf meinem Wunschzettel ganz oben steht die Implementierung eines nutzerfreundlichen, KI-gestützten Wörterbuchs, das den Komfort der DeepL-App in die nützlichen Funktionen eines CAT-Tools (Termdatenbank / Translation Memory) integriert.
Review
von Margarita Ruppel
Im Gegensatz zu mir hat der Teilnehmer bereits zuvor regelmäßig mit dem CAT-Tool memoQ gearbeitet, wenn auch nicht in Kombination mit dem DeepL-Plug-in, wie es im Workflow 6 des Experiments vorgegeben war. Viele seiner Beobachtungen und Schlüsse decken sich jedoch mit meinen.
Interessant finde ich zum Beispiel, dass auch bei ihm Umrechnungen von Maßeinheiten nicht funktionierten, weder durch DeepL noch durch memoQ (wie ich für möglich gehalten hätte), da er nach eigenen Angaben Google dafür bemühte. Eine solche eher simpel erscheinende Funktion, die buchstäblich »Rechenleistung« erfordert, würde ich von maschinellen Tools eigentlich erwarten.
Bei komplexeren Aufgaben, also zum Beispiel komplexeren Sätzen, macht Landes mit den Vorschlägen der MÜ dieselbe Erfahrung wie ich. Er übernimmt nur wenige simple Sätze direkt von DeepL und muss bei den meisten überprüfen, umschreiben oder ganz neu formulieren. Beim ersten Satz, der nicht auf Anhieb leicht zu verstehen ist, beschreibt er, dass er vom KI-Vorschlag zunächst auf die falsche Fährte gebracht wurde und sich für seine eigene Lösung später viel stärker vom Ausgangstext gelöst hat. Das deckt sich mit meiner Beobachtung, dass die MÜ die Freiheit, sich vom Original zu entfernen, beeinträchtigen kann. Wie Landes selbst schreibt, konnte er in diesem Fall viel am Text feilen, im realen Arbeitsalltag könnte dazu die Zeit wie auch die Konzentration nach sechs Stunden Übersetzen bzw. Posteditieren fehlen.
Schließlich konnte Landes, wie auch ich, bei dieser Arbeitsweise keine Zeitersparnis feststellen. Das zeigt, wie wenig Verlass auf die maschinelle Übersetzung ist und wie viel Eigenleistung des Übersetzers in das Ergebnis einfließt – nämlich nicht weniger als bei einer »herkömmlichen« Übersetzung. Es braucht seine Expertise, um die Fehler und Schwächen der MÜ (Inkonsistenzen, weniger sprachliche Vielfalt, fehlender »Sound« der Autorin, weniger fließender Zieltext durch Segmentierung) zu erkennen und zu korrigieren. Dieses Experiment verdeutlicht in meinen Augen, was der Mensch der KI noch um Längen voraushat: nämlich zu abstrahieren, einen tieferen Sinn zu erkennen, die Persönlichkeit einer Autorin aus dem Geschriebenen herauszulesen und zu transportieren, anstatt einen Text als Aneinanderreihung von Wörtern zu betrachten, deren Entsprechung in der Zielsprache vom Algorithmus nach Wahrscheinlichkeitsberechnungen festgelegt wird.
Zu dieser Schlussfolgerung passt auch, dass ich die beiden Stellen, die mir in der Übersetzung am positivsten durch originelle und lebendige Formulierungen aufgefallen sind, eindeutig der Leistung des Übersetzers zuschreiben kann:
- »Weil Pennington seine Prinzipien nicht über den Haufen wirft, nur um einen Reibach zu machen.«
- »Doch im Vergleich zum Ozeandampfer, der gnadenlos über die See pflügt, ist er nur eine vor sich hin dümpelnde Boje.«
Kreative und freiere Lösungen wie diese machen einen Text interessant und verleihen ihm Persönlichkeit, die die MÜ-Vorschläge laut Landes vermissen lassen. Sie stellen für ihn sogar eher eine »Art Störgeräusch« dar, was ich sehr treffend formuliert finde. Insgesamt sehe ich also viele Parallelen zwischen unseren Erfahrungen und Erkenntnissen in diesem Experiment.
Bild: Виталий Сова