
Hindernismaschine
Imke Brodersen berichtet von der ihr ungewohnten Arbeitsweise mit dem DeepL-Plug-in in Trados Studio 2021. Dabei schreckt sie in ihrer herkömmlichen Arbeitsweise vor dem Einsatz von Technik nicht zurück.
Der Ausgangstext (AT) ist ein Auszug von 895 Wörtern aus der Einleitung für das erzählende Sachbuch What We Don’t Talk About When We Talk About Fat der US-Amerikanerin Aubrey Gordon. Der Text beginnt sehr persönlich und ist aus Ich-Perspektive geschrieben.
Kulturelles Hintergrundwissen über die USA ist zum Übersetzen unverzichtbar. Die erwähnten amerikanischen Kleidergrößen und Gewichtsangaben werden für ein deutsches Sachbuch üblicherweise umgerechnet oder vergleichend ergänzt. Bei den Verweisen auf das amerikanische Gesundheitswesen muss ich als Übersetzerin entscheiden, wie viel Vorwissen aus amerikanischen Arztserien ich voraussetzen darf. Was soll adaptiert werden, was nicht? Wie kann ich ein möglichst breites Zielpublikum erreichen?
Technisch arbeite ich mit meinem gewohnten CAT-Tool Trados Studio 2021 in Kombination mit dem Terminologie-Tool MultiTerm 2021. Über MultiTerm greife ich normalerweise auf Termbanken zurück, die ich selbst über Jahre zu verschiedenen Themenfeldern angelegt habe. Das ist für meine Arbeitsgebiete mein zuverlässigstes Lexikon. Zusätzlich verfüge ich über eigene Autosuggest-Memories (siehe Screenshot) für meine Arbeitssprachen, mit deren Hilfe mir im Kontext passende Termini vorgeschlagen werden. Beides nutze ich in diesem Fall nicht und vermisse es schmerzlich.
Probleme bei der Terminologie-Extraktion
Die Erstellung eines Projekts für den Ausgangstext und das Anlegen einer neuen Termbank ist kein Problem. Für eine Terminologie-Extraktion mittels CAT-Tool bräuchte ich das Zusatztool MultiTerm Extract. Dieses Tool war zuletzt in der Version 2019 enthalten. Für aktuelle Programmversionen (2021 und 2022) ist es nicht mehr erhältlich. Es existiert zwar eine 100-seitige PDF-Anleitung von 2022 zum Umgang mit MT Extract vom Anbieter, doch als Freelancerin kann ich dieses Modul derzeit nicht erwerben.
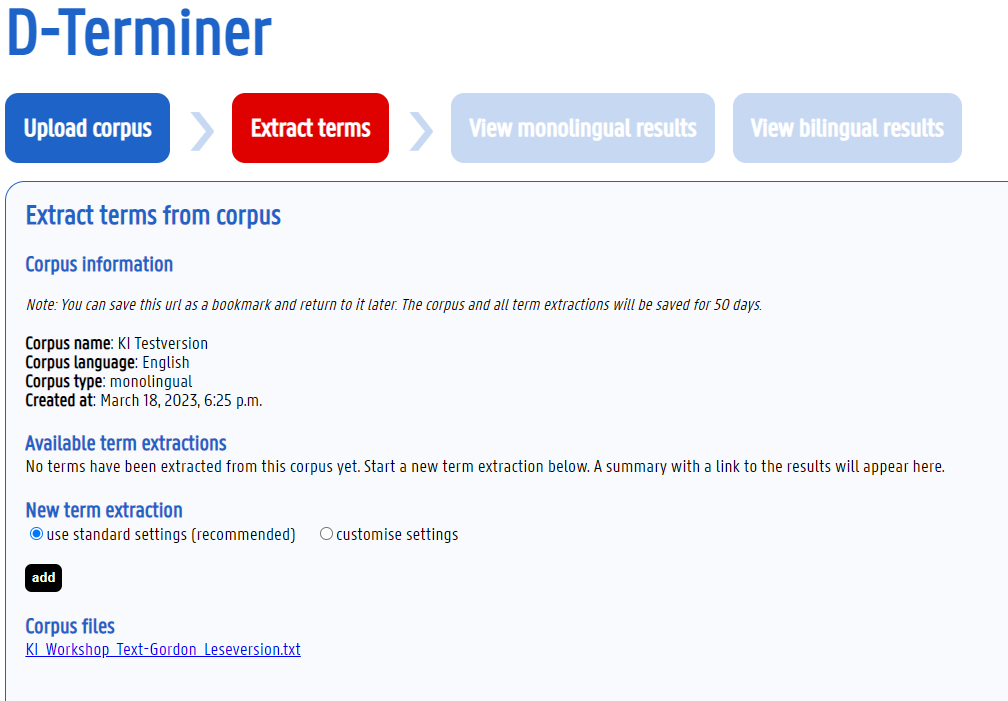
Alternativ habe ich den AT in das Tool D-Terminer eingegeben, doch es konnten keine Fachbegriffe ermittelt werden (siehe Screenshot). Der Korpus ist zu klein.
Eine manuelle Terminologie-Extraktion in einer anschließend importierten Excel-Tabelle wäre für diesen kurzen Text nicht sinnvoll. Die Terminologie lege ich ohnehin selten vorab fest, sondern erarbeite sie parallel zur Übersetzung. Nur Schlüsselbegriffe zur Abstimmung mit Redaktion und Lektorat landen in separaten Excel-Tabellen; alles andere wandert in meine Termbanken.
Das Suchen nach einer Lösung für die Terminologie-Extraktion kostete Zeit und zeigte mir, dass meine gegenwärtigen Arbeitsprozesse passender sind.
Segmente im CAT-Tool mit DeepL-Plug-in übersetzen
Für die Aktivierung des DeepL-Plug-ins brauche ich den Authentifizierungsschlüssel. Das DeepL-Konto, das ich 2019 für eine Fallstudie angelegt hatte, aber seitdem weder bezahle noch nutze, existierte noch. Mithilfe einer Video-Anleitung des Herstellers gelingt die Installation des Plug-ins, die Grundfunktionen werden im Video erklärt.
Maschinenübersetzung (MÜ) im CAT-Tool, Export, Prüfen
Die Rohübersetzung nur mit DeepL dauert Sekunden. Ich exportiere testweise die Rohübersetzung und markiere typische Fehler im Zieldokument: schiefe Wendungen, fehlende Umrechnungen, falsche Termini, falsche Erzählzeiten, Maskulinitäts-Bias der Maschine: Jede unklare Mehrzahl bei Personen ist männlich, wobei DeepL auch gern auf neutrale Begriffe wie »Verwandte« oder »Fremde« ausweicht. Ansonsten gibt es nur »Freunde«, »Arbeitskollegen«, »Chirurgen«, »Ärzte«, »Verteidiger«. Kein Satz bleibt ohne Anmerkung.
Da die Autorin sich im Text als queere Frau zu erkennen gibt, wäre eine konsequente Maskulinisierung von Personen sicher nicht in ihrem Sinne. An diesem Punkt informiere ich mich näher über die Autorin, sehe mir Fotos an und lese Einträge. Bei einer Übersetzung des gesamten Buchs würde ich auch Videos ansehen und einen oder zwei ihrer Podcasts anhören, um den passenden Tonfall zu finden.
Kontrolldurchlauf in Trados
Die Erstüberarbeitung in Trados mit Vergleich zum Ausgangstext entspricht nicht meiner normalen Arbeitsweise. Die Übersetzungsvorschläge klingen zwar glatt, aber ich muss jeden Satz anfassen. Gleichzeitig erstelle ich die Termbank für dieses Projekt (Schritt 1 und 2), notiere Links zu meinen Quellen und mache Anmerkungen für die Schlusskorrektur.
Was mir in dem kurzen Auszug dieser Einleitung fehlt, ist der Gesamtkontext: Worauf will die Autorin eigentlich hinaus? Mit welcher Wortwahl (z. B. Konnotationen von »dick« bzw. »fett« bereits in den ersten zwei Sätzen) führe ich die Lesenden von Anfang an in die gewünschte Richtung? Geht es vor allem um psychische und rechtliche Aspekte der Diskriminierung aufgrund von Gewicht und Umfang einer Person? Oder auch um medizinische Aspekte von Körperfett?
Spontan überprüfe ich in der Amazon-Vorschau die Gliederung und bestelle eine Taschenbuchausgabe (in der sofort verfügbaren E-Book-Ausgabe wäre gezieltes »Blättern« nicht möglich und Markieren weniger übersichtlich). Und siehe da, auf Seite 8 wird das im Kontext knifflige Wort »fat« von der Autorin definiert. Daraufhin lese ich deutsche Blogs, um mir den Stand der Diskussion auf Deutsch zu erschließen.
Bei der Nachbearbeitung in Trados fallen weitere Fehler auf, die mir bei der spontanen Erstdurchsicht entgangen sind. Ich fange an zu straffen und Sätze umzustellen, um einen gut lesbaren Text zu erzeugen. Solche Sätze würde ich auch ohne maschinellen Entwurf schreiben, hätte aber mehr Freiheit beim Formulieren. Die Überarbeitung nimmt mehr Zeit in Anspruch als eine normale Übersetzung, weil ich aufpassen muss, nicht versehentlich der DeepL-Vorgabe auf den Leim zu gehen und Fehler zu übernehmen. Am Ende ist exakt ein Zwei-Wort-Segment unangerührt: Der Name der Autorin (siehe Screenshot).
Kontrolldurchlauf in Word
Jenseits der Segmentierung durch Trados nehme ich beim Schlusslektorat weitere Änderungen im Zieldokument vor, werde mutiger und löse mich etwas mehr vom Ausgangstext. Insgesamt könnte ich dieses Buch mit meiner gewohnten Arbeitsweise (mit Trados, aber ohne Einsatz von DeepL) schneller und besser in eine gut lesbare Version bringen, die auch der Autorin gerecht werden würde. Die Einleitung bekäme gerade bei einem derart sensiblen Thema nach Abschluss der Gesamtübersetzung eine erneute Schlussüberarbeitung.
Review
von Hanna Reininger
Für diesen Review habe ich zunächst nur den Zieltext (ZT) und die Reflexion gelesen. Der übersetzte Text erscheint flüssig, kohärent und unterhaltsam. Die Autorin berichtet aus ihrer Perspektive über das von ihr täglich erlebte fat shaming und beschreibt ihre Strategien im Umgang damit. Doch einige Stellen im Text erscheinen unklar bzw. wenig idiomatisch, wie zum Beispiel:
- S. 1 mittig: »… einem Leben … 50 Kilo außer Reichweite …« [›außer Reichweite‹ verlangt meines Erachtens nach Längenmaß, nicht Gewichtsangabe]
- S. 2 unten: »Dicke … symbolisieren das Scheitern von Amerika, Kapitalismus, …« [›Kapitalismus‹ oder ›Scheitern des Kapitalismus‹?]
Weitere Stellen des ZT könnten noch etwas gestrafft werden:
- S. 1 oben: »… wiege ich 155 Kilogramm und trage KonfektionsgGröße 26 (was ungefähr der deutschen Damengröße 56 entspricht). … Vor drei Jahren wog ich gut 180 Kilogramm …«
- S. 1 unten: »… Verwandte, ArbeitskKollegen und Unbekannte …«
- S. 2 oben: »… dass ich nie eine MRT– oder CT-Aufnahme benötige.«
Und einige wenige Wiederholungen aufgelöst werden:
- S. 1 mittig: »… in Größe 24 – das war das größte, das ich …«
- S. 1 unten: »Manche Ärzte weigern sich, mich zu behandeln, und es gibt Praxen, die … nicht behandeln …«
- S. 3 unten: »Bedauerlicherweise musste ich … mit absoluter Gewissheit weiß … niemand rechtfertigen muss.«
Beim anschließenden Lesen des Ausgangstextes (AT) habe ich diesen als sehr rhythmisch und bildreich wahrgenommen. In ihm finden sich einige Alliterationen. Gegebenenfalls hätte noch mehr von diesen Textmerkmalen ins Deutsche »hinübergerettet« werden können.
In ihrem Reflexionstext beschreibt die Übersetzerin ihre – für eine Literaturübersetzerin eher ungewöhnliche – Verwendung des CAT-Tools Trados. Im Laufe der Jahre hat sie ihren persönlichen ›MÜ-Avatar‹ in Form von umfassenden Termbanken erstellt, auf die sie im Übersetzungsprozess zurückgreift. Bei diesem Versuch durfte sie diese jedoch nicht nutzen und vermisste sie schmerzlich. Sie zeigt den im KI-ZT nicht stringenten Umgang mit fat auf und hinterlegt ihre Entscheidung hierzu mit einer Recherche. Sie wählt »dick« anstelle von »fett«. Da die Autorin selbstbewusst zu ihrem Körper steht, hätte ich hier gegebenenfalls anders entschieden, denn schon zu Beginn des Vorworts erteilt sie einigen Euphemismen eine Abfuhr.
Die Erfahrungen der Übersetzerin ähneln meinen: Die Einbindung des DeepL-Plug-ins ist unproblematisch, die anschließende Übersetzung der AT-Segmente dauert nur wenige Sekunden. Bei der Überprüfung wird schnell klar, dass der KI-ZT viele Fehler und Ungenauigkeiten enthält. Jeder Satz birgt Änderungsbedarf. Das Post-Editing (PE) wird als herausfordernd empfunden, da der KI-ZT eng mit dem AT abzugleichen ist, um eine Übernahme von Fehlern auszuschließen.
Nach dem Lesen des AT scheint mir die Übersetzung an einigen Stellen freier als unbedingt notwendig. Dies lässt vermuten, dass mit dem PE erst eine Art Rohübersetzung entstanden ist, die aber nicht – mangels einer nicht vorgesehenen, erneuten intensiven Auseinandersetzung mit dem AT – an diesen wieder »angenähert« wird.
Positiv fällt auf, dass mit dem PE die Länge des ZT sinkt:
- AT: 895 W / 5.096 Z (-> 100 %)
- KI-ZT: 917 W / 6.238 Z (-> 122 %)
- ZT: 885 W / 6.197 Z (-> 117 %)
Fazit: Das Post-Editing der von einer KI erstellten Übersetzung eines literarischen Texts scheint auch für diesen Auszug eines Sachbuch-Vorworts wenig sinnvoll bzw. arbeitssparend.
Bild: Виталий Сова