
Maschinelle Übersetzung: ein Manifest
Der unüberlegte Einsatz von maschineller Übersetzung greift um sich – eine Entwicklung, die den finanziellen Druck auf Selbstständige verschärft, oft zu schlechter Textqualität führt und dem anspruchsvollen Übersetzungsprozess nicht gerecht wird. Bereits 2021 forderte der Dachverband für audiovisuelle Übersetzung AVT Europe in seinem »Machine Translation Manifesto«, die Entscheidungsautonomie der Übersetzer*innen zu wahren. Dieses Manifest hat Daniel Landes, Mitglied des AVTE, nun erstmals ins Deutsche übertragen.
Zusammenfassung
- Der richtige Einsatz von maschineller Übersetzung (MÜ) erfordert Kompetenz, Fachwissen und sorgfältige Planung. Wir sind der Überzeugung, dass vollautomatische Lokalisierungsprozesse in absehbarer Zeit nicht möglich sind.
- Die Qualität der maschinellen Übersetzung hängt von vielen Faktoren ab: von der Komplexität des Ausgangstextes, dem Korpus, mit dem die MÜ-Engine trainiert wurde, der Kreativität des Originals usw.
- Bei audiovisuellen Inhalten beeinflussen Ton und Bild die Bedeutung des Textes. MÜ-Engines verstehen keinen Kontext und reproduzieren lediglich vorhandene Übersetzungen. Daher ist maschinelle Übersetzung für den audiovisuellen Bereich weniger gut geeignet.
- Übersetzende sind an der Entwicklung von MÜ-Lösungen kaum beteiligt, und die allgemeine Annahme lautet, dass alle Übersetzenden gleich arbeiten, obwohl es viele unterschiedliche Arbeitsstile gibt.
- Bessere Kommunikation zwischen Entwickler*innen und audiovisuellen Übersetzenden könnte dazu beitragen, den Fokus von MÜ auf andere nützliche Technologien zu verlagern, wie z. B. bestimmte Funktionen von CAT-Software (computergestützter Übersetzungssoftware), Diktierfunktionen und Tools zur Qualitätssicherung.
- Befürworter*innen sprechen zwar von garantierten Effizienzgewinnen dank MÜ, die Überarbeitung einer schlechten Übersetzung kann jedoch länger dauern als eine Neuübersetzung. Manche Übersetzende liefern schlechtere Qualität ab, wenn sie MÜ verwenden. Das bedeutet, dass sich der nötige Arbeitsaufwand lediglich von der Übersetzung auf das Lektorat verlagert.
- Der skrupellose Einsatz von MÜ wird über kurz oder lang dazu führen, dass fähige Übersetzende abwandern und es zu einem Fachkräftemangel kommt. Die gesamte Branche ist damit langfristig gefährdet.
- Um die Zukunftsfähigkeit der Branche zu sichern, müssen die Arbeitsbedingungen von Übersetzenden verbessert werden. Dazu zählen eine angemessene Vergütung, sowohl für die Übersetzungsarbeit als auch für die Daten, die für das Training von MÜ-Engines verwendet werden, die Gewährleistung des Status als Urheber*innen, die Festlegung des erwarteten Outputs sowohl für Übersetzende als auch für Post-Editor*innen und die Einhaltung von Qualitätsstandards.
- Ethische Aspekte sind nicht weniger wichtig: Der Einsatz von MÜ muss klar gekennzeichnet sein und darf nicht als menschliche Übersetzung ausgegeben werden. Übersetzende sind sich oft nicht bewusst, dass ihre Arbeitsergebnisse zum Training von MÜ-Engines verwendet wird, und sie werden momentan auch nicht dafür vergütet. Der Einsatz von MÜ verfälscht den einzigartigen Stil von Übersetzenden, und die daraus resultierende Sprache wird eintöniger und homogener. Auch die ökologischen Kosten von MÜ sollten berücksichtigt werden.
- Wir befürworten das Konzept des »augmentierten Übersetzers«, bei dem der Mensch im Mittelpunkt steht und seine Fähigkeiten mithilfe von Technik optimiert.
Einleitung
Der Quantensprung im Feld der maschinellen Übersetzung (MÜ) innerhalb der letzten zehn Jahre hat die Lokalisierungsbranche nachhaltig verändert. Während einige bereits das Ende der Humanübersetzung feiern und das Zeitalter der »Post-Lokalisierung« einläuten, gilt es zu bedenken, dass Künstliche Intelligenz (KI) lediglich große Mengen an Referenzdaten nutzt, um häufig korrekte Ergebnisse zu erzielen. Menschliche Übersetzende wissen hingegen, wie Wörter und Konzepte zueinander in Beziehung stehen, was die solidere Grundlage für eine hochwertige Übersetzung darstellt.
Aljoscha Burchardt, leitender Forscher am Deutschen Forschungszentrum für Künstliche Intelligenz, drückt es folgendermaßen aus: »MÜ ist zwar ein schlauer Papagei, aber letztendlich doch nur ein Papagei« (Augmented Translation, Dr. Arle Lommel, CSA Research, 34:37).
Bedauerlicherweise sind die Arbeitsbedingungen von menschlichen Übersetzenden von jeher schlecht, und der jüngste Hype um KI und damit auch maschinelle Übersetzung hat die Situation nur noch verschlimmert.
Da MÜ nicht mehr aus der Welt wegzudenken ist und durchaus Potenzial hat, möchten wir einen Überblick über den aktuellen Stand der Dinge geben und Richtlinien für KI-gestützte menschliche Übersetzung vorschlagen sowie Empfehlungen für die Zukunftsfähigkeit der Branche im Allgemeinen aussprechen.
Was maschinelle Übersetzung leisten kann
Aktuelle Situation
Entgegen der Annahme, dass KI mittlerweile problemlos als persönlicher Dolmetscher fungiert, erfordert ihr richtiger Einsatz Kompetenz, Fachwissen und sorgfältige Planung. Wir sind weit davon entfernt, einfach einen Text in die grafische Benutzeroberfläche einer MÜ-Engine zu kopieren und eine hochwertige Übersetzung zu erhalten. Der Mensch ist nach wie vor ein wesentlicher Bestandteil des Lokalisierungsprozesses, und oft ist traditionelle Übersetzung die einzige Möglichkeit, ein adäquates Ergebnis zu erzielen. Die Qualität der maschinellen Übersetzung ist nämlich sehr variabel, da sie von vielen Faktoren abhängt:
- Ist der Ausgangstext so geschrieben, dass er von der Maschine gut übersetzt werden kann? Werden viele Abkürzungen oder Fachjargon verwendet, wie es bei einem Videospielstudio der Fall wäre, das über das neueste Update seines Spiels spricht, oder hält sich der Text an gängige sprachliche Standards und wurde von einem professionellen Autor (z. B. einer Journalistin) geschrieben?
- Erfordert der Inhalt eine kreative Übersetzung (z. B. bei einem High-Fantasy-Drama) oder ist er repetitiv und folgt erkennbaren Mustern (z. B. bei einem Rezept)?
- Wie gut wurde die MÜ-Engine für das jeweilige Fachgebiet trainiert und welche Qualität haben die verwendeten Korpora (Datenbanken mit Sätzen in Ausgangs- und Zielsprache)? Oder ist die Engine ein Alleskönner und setzt in Sachen Trainingsdaten auf Quantität statt Qualität?
- Gibt es für das betreffende Sprachenpaar umfangreiche Korpora oder muss eine Relaissprache (dritte Sprache, z. B.: Ausgangssprache > Englisch > Zielsprache) für die Übersetzung verwendet werden?
Diese und weitere Faktoren beeinflussen die Qualität der maschinellen Übersetzung, so dass man kaum allgemeine Aussagen treffen kann. Bei richtigem Einsatz und unter Berücksichtigung des jeweiligen Szenarios kann die Technik menschliche Übersetzende unterstützen. Wir möchten, dass KI in Zukunft Menschen nicht ersetzt, sondern ihre Fähigkeiten augmentiert. Die Maschine kann große Datenmengen schnell analysieren und dem Menschen relevante Ergebnisse präsentieren, was sich in Bezug auf Effizienz und Qualität als unschätzbar wertvoll erweisen könnte.
Da KI lediglich bestehende Übersetzungen reproduziert, kann sie keine kreativen Lösungen finden. Sie sucht nach vorhandenen Wörtern und Sätzen in den verfügbaren Trainingsdaten und konstruiert daraus eine Übersetzung. Wie sie zu diesen Ergebnissen kommt, ist allerdings nicht vorhersehbar, so dass manchmal katastrophale Fehler (völlig unbrauchbare Übersetzungen) auftreten. Außerdem versteht die KI keinen Kontext (oder zumindest nur begrenzt). Diese Einschränkung ist auf die Konzeption der Algorithmen zurückzuführen und wird auch in naher Zukunft bestehen bleiben. Expert*innen zufolge stellen ein paar Seiten in einem Buch das aktuelle Limit dar, welches bisher aber noch nicht erreicht wurde.
Bei der Lokalisierung von audiovisuellen Inhalten ist jedoch der Kontext entscheidend. Das gesamte Bild – Szene, Tonfall und Gesten – beeinflusst die Bedeutung des Textes, und solange Maschinen nicht in der Lage sind, diese Elemente zu berücksichtigen, versagt MÜ bei audiovisueller Übersetzung sowie bei allen (kreativen) kontextsensitiven Übersetzungen.
Funktionen, die sich in Entwicklung befinden
Maschinen werden zwar vermutlich keine ganzen Bücher lesen und verstehen können, doch Branchenexpert*innen können uns Einblicke in die kleineren Fortschritte der Technologie verschaffen. Sowohl Evgeny Matusov als auch Yota Georgakopoulou schreiben über Verbesserungen, die in unseren täglichen Arbeitsabläufen Einzug halten könnten.
Bei der Vor- und Nachbearbeitung von Texten könnten Metadaten der KI helfen, prachregister, Textlänge und Geschlecht von Charakteren zu berücksichtigen, und audiovisuelle Übersetzende könnten diese Informationen auch von Segment zu Segment anpassen. Außerdem könnte eine intelligente automatische Textsegmentierung den Bearbeitungsaufwand für korrekt formatierte Untertitel verringern.
Eine automatische Grammatikprüfung könnte grammatikalische Fehler beseitigen, die Implementierung eines Glossars könnte die Konsistenz verbessern, und mithilfe von Indikatoren für die geschätzte Übersetzungsqualität könnten sich automatisch Vorschläge herausfiltern lassen, die bestimmten Standards nicht entsprechen.
In den kommenden Jahren werden voraussichtlich auch MÜ-Engines für Sprachenpaare erscheinen, die Übersetzungen via Relaissprache überflüssig machen.
Auch wenn diese Funktionen die Arbeit mit MÜ erleichtern, bezweifeln wir, dass vollautomatische Lokalisierungsprozesse ohne menschliches Zutun in absehbarer Zeit möglich sind.
Einsatzmöglichkeiten von maschineller Übersetzung
Aktuelle Situation
Übersetzende sind an der Entwicklung von MÜ-Lösungen kaum beteiligt, und obwohl sie wertvolle Rückmeldung geben könnten, werden sie kaum dazu befragt. Folglich werden ihre Bedürfnisse und Nutzererfahrungen auch nicht berücksichtigt. Es wird davon ausgegangen, dass alle Übersetzenden gleich arbeiten, dabei gibt es unterschiedliche Ansätze bei der Verwendung von MÜ. Während einige Übersetzende MÜ-Vorschläge nur gelegentlich nutzen und sich nicht zu sehr davon beeinflussen lassen wollen, ziehen andere es vor, den maschinellen Output umzuformulieren. Allerdings erscheinen MÜ-Vorschläge in CAT-Tools oft direkt im Arbeitsfeld von Übersetzenden und lassen sich nicht einfach ausblenden.
Bessere Kommunikation zwischen Entwickler*innen und audiovisuellen Übersetzenden könnte dazu beitragen, den Fokus von MÜ auf andere Technologien zu verlagern. Diese werden oft übersehen, obwohl sie einen viel höheren praktischen Nutzen für Übersetzende haben und der Qualität im Allgemeinen viel zuträglicher wären. In diese Kategorie fallen eine Reihe von Funktionen aus CAT-Tools, Diktierfunktionen sowie weitere technische Lösungen. Während sie in anderen Übersetzungsbereichen zum Alltag gehören, kommen sie in der audiovisuellen Übersetzung so gut wie nicht zum Einsatz oder werden nicht unterstützt.
In der Regel sind es Agenturen oder Endkund*innen, die entscheiden, ob und wie MÜ bei einem bestimmten Projekt eingesetzt wird. Diese Entscheidung wird oft von Projektmanager*innen getroffen, die keine Ausbildung oder Erfahrung in der Übersetzung haben, während Übersetzende, die Expert*innen auf dem Gebiet sind, keinerlei Mitspracherecht haben. Manchmal werden Übersetzende angewiesen, möglichst viel Textmaterial der maschinellen Übersetzung beizubehalten. Dieser Ansatz wird als »einfaches Post-Editieren« bezeichnet. Im Gegensatz zum »vollständigen Post-Editieren«, bei dem das Produkt die Qualität einer menschlichen Übersetzung erreichen muss, sollen Leser*innen beim einfachen Post-Editieren lediglich die grobe Bedeutung verstehen, ohne dass das Produkt die Qualität einer menschlichen Übersetzung erreicht. Das mag für interne Kommunikation oder die Moderation von Kanälen in den sozialen Medien ausreichen, ist für die meisten audiovisuellen Inhalte jedoch völlig ungeeignet.
Obwohl die enthusiastischen Aussagen von MÜ-Befürworter*innen von garantierten Effizienzgewinnen sprechen, bezeugen die meisten Übersetzenden, dass die Korrektur einer schlechten Übersetzung – egal, ob sie von einer Maschine oder von einem Menschen stammt – länger dauert als eine Neuübersetzung. Tatsächlich beklagen Lektorierende (je nach audiovisueller Disziplin auch QCer, Proofreader, Adaptor usw. genannt), dass manche Übersetzende schlechtere Qualität abliefern, wenn sie MÜ verwenden. Das bedeutet, dass sich der nötige Arbeitsaufwand lediglich von der Übersetzungsphase auf die Qualitätssicherungsphase verlagert, wobei die Bezahlung des Lektorats jedoch gleich bleibt.
Was wir uns wünschen
- Eine benutzerfreundliche, intuitive Oberfläche, welche die Konzentration fördert. Um das zu erreichen, sollten Übersetzende bei der Konzeption und der Implementierung von MÜ-Abläufen eingebunden werden.
- MÜ sollte als optionales Werkzeug angesehen werden, das die menschliche Kreativität stimuliert, anstatt sie einzuschränken. In der Praxis möchten wir in Arbeitsprogrammen MÜ-Vorschläge auf Knopfdruck ein- und ausblenden oder einfügen können. Die Tastenkombinationen dafür sollten sich frei konfigurieren lassen. Idealerweise sollte man auch nur MÜ-Vorschläge anzeigen lassen können, die einer bestimmten Qualität entsprechen. Die Darstellung der MÜ-Ergebnisse sollte sich zudem personalisieren lassen, um verschiedenen Arbeitsweisen gerecht zu werden: Die Korrektur des MÜ-Vorschlags im Textfeld sollte ebenso möglich sein wie die Eingabe von Text in einem leeren Feld, während der Vorschlag (auf Knopfdruck) separat angezeigt wird.
- Neben MÜ wünschen wir uns auch andere, traditionellere Tools. Übersetzende sollten die volle Kontrolle über die Arbeitsumgebung haben und Werkzeuge je nach Bedarf mithilfe von personalisierbaren Tastenkombinationen ein- und ausschalten können. Folgende Funktionen, von denen einige aus CAT-Anwendungen bekannt sind, finden wir besonders hilfreich:
- Eine durchsuchbare Translation Memory (Stichwort Konkordanzsuche), mit der sich unkompliziert vorhandene Übersetzungen von verwandten Inhalten, z. B. von weiteren Episoden/Staffeln derselben Serie, oder andere zweisprachige Inhalte aufrufen lassen. Werden sowohl Translation Memorys (TMs) als auch MÜ eingesetzt, sollte klar erkennbar sein, welcher Vorschlag aus welcher Ressource stammt. MÜ könnte zudem TM-Produkte verbessern und z. B. auch passende Teilsätze oder Terminologie aus TM-Segmenten vorschlagen.
- Eine Termdatenbank, die schnellen Zugriff auf Glossare mit wichtigen Namen, Zitaten, Begriffen usw. gewährt. Mithilfe von KI könnten diese Ressourcen weiter verbessert werden (Automated Content Enrichment – automatisierte Optimierung von Inhalten durch Hintergrundwissen).
- Eine Autovervollständigung, die antizipiert, welche Wörter wir bei der Übersetzung eines bestimmten Satzes höchstwahrscheinlich schreiben werden, und uns so Tipparbeit erspart.
- Eine Diktierfunktion, die auf Umgangs- und Alltagssprache trainiert und um das Einfügen von Zeitstempeln oder Segmentieren von Text per Sprachbefehl erweitert werden kann.
- Eine aktuelle Rechtschreibprüfung, die auch mit Umgangs- oder Alltagssprache zurechtkommt und besser funktioniert als quelloffene Varianten, welche schon seit Längerem nicht mehr überarbeitet wurden und für einige Sprachen unzureichende, fehlerhafte Wörterbücher enthalten.
- Qualitätssicherungstools, die sich nicht nur auf technische Aspekte wie Lesegeschwindigkeit und Pausen zwischen den Untertiteln konzentrieren, sondern auch auf sprachliche Aspekte. Erkannt werden sollten z. B. nachgestellte Leerzeichen, doppelte Leerzeichen, Wortwiederholungen, grammatikalische Fehler, Wörter, die nicht am Zeilenende stehen sollten, und Glossarverstöße. Die Unterstützung von regulären Ausdrücken (Regex) beim Suchen und Ersetzen wäre für den Arbeitskomfort ebenfalls wichtig.
- Anwendungen, welche die Zusammenarbeit von Übersetzenden bei größeren Projekten erleichtern, entweder innerhalb einer Sprache (z. B. mehrere Personen, die an einer Serie arbeiten) oder sprachenübergreifend (z. B. mehrere Übersetzende, die jeweils in ihre Zielsprache arbeiten) und rollenübergreifend (Übersetzung, Qualitätssicherung, Vorlagenerstellung, Autor*innen usw.).
- Neue innovative Werkzeuge, die in Zusammenarbeit mit Übersetzenden entwickelt werden und linguistische Korpora verwenden. Ein Beispiel dafür wäre eine lemmabasierte Suche nach Übersetzungsäquivalenten (word alignments – Wortentsprechungen) oder der unkomplizierte Zugriff auf bestehende spezialisierte Wörterbücher.
Faire Bezahlung, Zukunftsfähigkeit und Qualität
Aktuelle Situation
Im Bereich der audiovisuellen Übersetzung werden technische Neuerungen in der Regel mit schlechterer Vergütung assoziiert, da in der Vergangenheit viele solcher Fälle zu Honorarsenkungen geführt haben, darunter z. B. die Einführung von Fuzzy Matches in der Spielelokalisierung und der Einsatz von automatischer Spracherkennung in der Transkription.
Ein weiteres Beispiel hierfür kommt aus der Untertitelungsbranche. Um die Effizienz zu steigern, haben Unternehmen die Aufgabe einer einzigen Spezialistin, der Untertitlerin, fragmentiert und auf mehrere Personen aufgeteilt. Es gibt mittlerweile Vorlagenersteller*innen, Vorlagenlektor*innen, Übersetzende, Übersetzungslektor*innen usw. Weil diese jedoch »weniger Arbeit« zu erledigen haben, werden sie auch schlechter bezahlt. Die Honorarkürzungen waren allerdings unverhältnismäßig hoch, weshalb heutzutage nur sehr wenige Untertitelungsexpert*innen ein Einkommen verdienen, das ihren Qualifikationen, Fähigkeiten und ihrer Erfahrung entspricht.
Bereits vor dem Einsatz von MÜ wurden viel zu niedrige Tarife gezahlt, nicht zuletzt, weil sie über zehn Jahre lang stagnierten und nicht an die Inflation angepasst wurden. Die Beliebtheit von MÜ bei Unternehmen hat jedoch aufgrund der angeblich »enormen Effizienzgewinne« zu einer noch stärkeren Fragmentierung des Arbeitsablaufs (durch Post-Editing und Metadatenmanagement) und zu noch drastischeren Honorarkürzungen geführt. Audiovisuelle Übersetzende sehen hingegen Behauptungen in Bezug auf gesteigerte Effizienz kritisch.
Der Wechsel zum Post-Editing hat nicht nur zu geringerer Bezahlung und gesunkener Arbeitszufriedenheit geführt, sondern bedroht außerdem den Urheber*innenstatus von Übersetzenden. Sollte der Gesetzgeber nicht angemessen reagieren, könnte der Einsatz von maschineller Übersetzung dazu führen, dass audiovisuelle Übersetzende ihr Urheber*innenrecht und somit auch Anspruch auf Tantiemen verlieren, die bis zu 50 Prozent ihres Einkommens ausmachen.
Diese Faktoren haben das Problem der Abwanderung von Fachkräften, die auch vor Einsatz von MÜ bereits eingesetzt hatte, noch weiter verschärft. Expert*innen verlassen das Berufsfeld, weil sie woanders bessere Arbeitskonditionen vorfinden, und Hochschulabsolvent*innen tun sich schwer, in unserer Branche Fuß zu fassen. Das wiederum trägt zum »Fachkräftemangel« bei, der in aller Munde ist.
Auch die Übersetzungsqualität leidet unter dem Einsatz von MÜ und wird sich weiter verschlechtern, sollten keine Gegenmaßnahmen getroffen werden. Dieses Problem könnte sich weiter intensivieren, wenn MÜ-Engines zukünftig zu Trainingszwecken wieder mit maschinell übersetzten Inhalten gefüttert werden. Die Effizienzmaximierung scheint sämtliche Diskussionen der Branche zu dominieren, während das Thema Qualität nur kurz oder überhaupt nicht angesprochen wird. Da Post-Editor*innen oft angewiesen werden, den Output der Maschine so wenig wie möglich zu verändern, oder aufgrund von niedrigen Tarifen und Zeitdruck nach dem Motto »Das ist gut genug« arbeiten müssen, kann Qualität keine Priorität sein. Doch hierbei leiden nicht nur Übersetzungen, sondern auch die psychische Gesundheit der Einzelnen.
Angesichts der schlechten Tarife, Arbeitsbedingungen und der fragwürdigen Qualität sowie der Tatsache, dass erfahrene Übersetzende die Branche verlassen und durch Studierende, Amateur*innen und Teilzeitkräfte ersetzt werden, fürchten wir um den langfristigen Fortbestand unseres Berufsstandes und prangern den ausbeuterischen Einsatz von MÜ an.
Was wir fordern
- Die MÜ-Honorare für Übersetzende sollten mindestens an die Inflation der letzten zehn Jahre angeglichen werden, um den Gehältern von ähnlich qualifizierten Arbeitnehmer*innen in anderen Berufsfeldern zu entsprechen. Dabei gilt es auch, Leistungen zu beachten, die Angestellten für gewöhnlich zugutekommen, wie bezahlte Krankheitstage, bezahlter Urlaub, Krankenversicherung, Rentenvorsorge, Mutterschutz usw.
- Der Effizienzgewinn durch MÜ sollte in erster Linie dazu genutzt werden, der steigenden Nachfrage gerecht zu werden, was Grund genug für Investitionen in MÜ-Schulungen und -Implementierung wäre. MÜ könnte für weniger anspruchsvolle Projekte eingesetzt werden, so dass hochqualifizierte audiovisuelle Übersetzende für anspruchsvolle Projekte verfügbar sind.
- Die Vergütung für das Post-Editieren von maschinellen Übersetzungen sollte in einem angemessenen Verhältnis zum hohen Maß an Fachwissen stehen, das dafür erforderlich ist.
- Übersetzende sollten darüber informiert werden, dass ihre Arbeit für das Training einer MÜ-Engine verwendet wird, und entsprechend vergütet werden.
- Der Urheber*innenstatus von Übersetzenden muss auch bei der Verwendung von MÜ erhalten bleiben.
- Wenn das erwartete tägliche Pensum von Post-Editor*innen kalkuliert wird, sollten Faktoren wie die psychische Gesundheit berücksichtigt werden, da MÜ nicht so schnell korrigiert werden kann wie eine Humanübersetzung.
- Qualität sollte im Vordergrund stehen.
- Um diese zu gewährleisten, müssen Fachkräfte angestellt und regelmäßig fortgebildet werden sowie kontinuierlich Qualitätskontrollen durchgeführt werden.
- Die Beurteilung der Qualität und das Korrektorat sind unterschiedliche Schritte innerhalb des Arbeitsablaufs. Das Lektorat sollte nicht gleichzeitig Korrektur lesen und die Qualität beurteilen müssen. Es ist deutlich zeitaufwendiger, bei jeder vorgenommenen Änderung Fehlertyp und Schweregrad festzuhalten, was eine negative Auswirkung auf die Arbeit haben kann.
- Die Qualitätsbewertung sollte nicht ausschließlich auf identifizierten Fehlern beruhen, da bei diesem Ansatz die Stärken eines Textes, wie z. B. kreative Lösungen und idiomatische Ausdrücke, außer Acht gelassen werden.
- Die Qualitätsbeurteilung sollte sich nicht nur auf die Leistungen von Übersetzenden und Post-Editor*innen beschränken, sondern auch das Lektorat umfassen.
- Es gilt zu bedenken, dass sich verlässliche Lektor*innen schwerer finden lassen als verlässliche Übersetzende.
Der ethische Aspekt von maschineller Übersetzung
Wie viele andere leistungsstarke technische Entwicklungen ist auch maschinelle Übersetzung (MÜ) nicht frei von ethischen Problemen, die vor allem auf skrupellose Praktiken zurückzuführen sind. Ein Beispiel dafür sind Unternehmen, die MÜ als menschliche Übersetzung ausgeben oder ihren Kund*innen nicht mitteilen, ob MÜ für den Lokalisierungsprozess eingesetzt wurde. Die meisten Filmemacher*innen, Produzent*innen und Urheber*innen würden sich wahrscheinlich gegen den Einsatz von MÜ bei der Übersetzung ihrer Werke wehren, selbst wenn Post-Editor*innen anschließend nachbessern.
Auch Übersetzende werden nicht darüber informiert, ob die Früchte ihrer Arbeit zum Training von MÜ-Engines eingesetzt werden, und werden nicht um Erlaubnis gefragt, was in einigen Ländern als Verstoß gegen das Urheberrecht gelten könnte (Anm. d. Red.: In Deutschland ist dies durch den § 44b UrhG zum Text und Data Mining rechtlich erlaubt). Generell bleibt die Meinung von Übersetzenden zu MÜ und Post-Editing weitgehend unberücksichtigt, obwohl viele offen erklären, dass sie keine maschinell erstellten Texte korrigieren wollen und dass ihr kreativer, ja sogar künstlerischer Beruf nicht zur mechanischen Routinearbeit ausarten soll.
Ein weiterer unerwünschter Nebeneffekt der Einführung des Post-Editings ist der Verlust des einzigartigen Stils von Übersetzenden sowie ihrer sprachlichen Markenzeichen. Unternehmensmaterialien, Präsentationen und E-Learning-Kurse mögen zwar für den Einsatz von MÜ geeignet sein und profitieren nicht im selben Ausmaß wie Unterhaltungsmedien von der »Stimme der Übersetzerin«, doch was ist mit Büchern, Filmen und Videospielen, bei denen Menschsein und Kreativität eine entscheidende Rolle spielen? Untersuchungen zufolge verlieren Übersetzende beim Post-Editing von MÜ etwa ein Drittel der stilistischen Merkmale, die ihre individuelle Stimme ausmachen.
Das könnte zur Folge haben, dass Sprache immer fader und homogener wird und an Vielfalt sowie linguistischem Reichtum einbüßt.
Darüber hinaus sind, wie bereits erwähnt, die Urheber*innenrechte im Zeitalter von MÜ noch nicht ausreichend erörtert worden, und die Frage nach einer geeigneten Gesetzgebung ist weiterhin offen. Da derzeit nicht klar ist, wem der Text gehört, der durch die Zusammenarbeit von Maschine und Post-Editor*in entstanden ist, könnten audiovisuelle Übersetzende das Recht auf Namensnennung verlieren und zu stummen Rädchen in der Lokalisierungsmaschine werden. (Anm. d. Red.: Nach deutschem Recht können nur Menschen und keine Maschinen Urheber*innen eines Werks sein. Beim Post-Editing literarischer Texte wird in der Regel eine Schöpfungshöhe erreicht, die Post-Editor*innen zu Urheber*innen macht.)
Zu guter Letzt müssen wir für MÜ und KI, wie auch für alle anderen technischen Produkte in unserem digitalen Zeitalter, einen ökologischen Preis bezahlen, da das Training von MÜ-Engines und deren Einsatz eine enorme Menge an Energie erfordert.
Ein Blick in die Zukunft
Maschinen sind zwar seit ihren Anfängen als regelbasierte Übersetzungsprogramme schon weit gekommen sind, doch können sie dem Menschen unter realen Bedingungen noch nicht das Wasser reichen und werden auch in naher Zukunft nicht dazu in der Lage sein. Aus diesem Grund nimmt der Mensch trotz des technischen Fortschritts auch weiterhin eine Schlüsselfunktion ein und bleibt ein essenzieller Bestandteil unserer Branche. Deshalb muss unabdingbar auf seine Bedürfnisse eingegangen werden.
In seinem Vortrag über augmentierte Übersetzung gibt Dr. Arle Lommel von CSA Research einen wertvollen Ausblick auf eine Zukunft, in welcher der Mensch weiterhin im Mittelpunkt von Übersetzungsabläufen steht. In dieser Zukunft werden Übersetzende nicht durch KI ersetzt oder zu Post-Editor*innen gemacht, sondern sie optimieren ihre Fähigkeiten und erhöhen ihr Arbeitstempo sowie ihren Arbeitskomfort. Übersetzenden stehen zwar sämtliche Spitzentechnologien der nächsten Generation zur Verfügung, doch sie sind nicht gezwungen, sie auch einzusetzen. Stattdessen können sie sich für die Tools entscheiden, die ihrer Meinung nach für das jeweilige Projekt am besten geeignet sind: automatisch um Hintergrundwissen erweiterte Glossare für rechercheintensive Aufgaben, optimierte Translation Memorys und adaptive neuronale maschinelle Übersetzung für Aufträge mit vielen Fachbegriffen und Wiederholungen oder auch reine Humanübersetzung für kreative Texte.
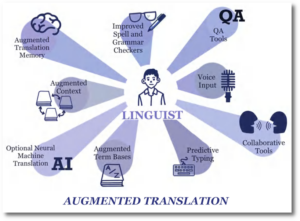
Wir wünschen uns, dass diese Vision Realität wird. Wenn wir die Position von Übersetzenden mithilfe von MÜ stärken und ihre Arbeitsbedingungen verbessern, können wir eine nachhaltige Zukunft für den Bereich der audiovisuellen Übersetzung gewährleisten und auch weiterhin Geschichten aus verschiedenen Ländern und Kulturen erzählen.
Doch dazu ist ein ständiger Dialog zwischen allen Beteiligten erforderlich, damit die Bedürfnisse aller erfüllt werden können. Außerdem sollten Aspekte wie Qualität, kognitive Belastung, psychische Gesundheit und Zufriedenheit von Arbeitskräften im Kontext von MÜ erforscht werden, um ein gesundes, produktives und nachhaltiges Arbeitsumfeld zu schaffen. Da sich die Forschung bisher hauptsächlich mit juristischen und technischen Texten beschäftigt hat, sollte das Hauptaugenmerk dabei auf kreativer Übersetzung liegen. Einsparungen, Druck auf externe Mitarbeitende und die Abschaffung menschlicher Übersetzender auf der Grundlage eines oberflächlichen Verständnisses von MÜ sind inakzeptabel.
Wir hoffen, dass dieses Dokument als Grundlage für Entwicklungen im Bereich der augmentierten Übersetzung dienen und die Beziehungen zwischen allen Beteiligten verbessern kann. Schließlich ging es in unserer Branche schon immer darum, zur Verständigung beizutragen und die Welt zusammenwachsen zu lassen.
Text: Max Deryagin, Miroslav Pošta, Daniel Landes
Lektorat des englischen Textes: Vanessa Wells, Claudia Carrington
Übersetzung: Daniel Landes
Konsultierung: Estelle Renard
Grafik »Augemented Translation«: Emma Carraud (inspiriert von CSA Research)
Erstveröffentlichung 2021 von Audiovisual Translators Europe (AVTE) unter dem Titel »Machine Translation Manifesto«
Beitragsbild: Melisa